An introduction to the binary_c
framework: software to make populations of single and binary stars on your computer(s).
Version 2.3
Warning: binary_c is always under development, so details are likely to change.
Version 2.3
Warning: binary_c is always under development, so details are likely to change.
top1 Disclaimer and Licence ¶
1.1 Disclaimer¶
Robert Izzard (henceforth RGI) is not responsible for anything you do with this code, for the results, quality of code or results, etc. it is up to you to make sure you get things right! You can check every line of source code if you like. While RGI has done his best to make sure everything that follows (and in his papers) is correct there are certainly bugs and omissions. Please, if you find one, can you let him know, preferably through the gitlab bug reporting interface https://gitlab.com/binary_c/binary_c/-/issues or by email.
1.2 Licence¶
1.3 Websites¶
- The main binary_c website is at https://binary_c.gitlab.io/
- binary_c ’s main git repository is at https://gitlab.com/binary_c/binary_c
- Most binary_c development is communicated through the binary Slack channel https://binaryslack.slack.com.
- binary_c is on Twitter at https://twitter.com/binary_c_code
- binary_c is on Facebook at https://www.facebook.com/groups/149489915089142
- binary_c is on YouTube at https://www.youtube.com/channel/UCsWzzMdthAs5LMmDnXEqzrg
1.4 Mailing lists and Slack¶
Most binary_c chat goes in the Slack channel, but there are also two mailing lists for binary_c
, both on Google’s “groups” service.
- We have a Slack workspace for binary_c , the “BinarySlack”, at https://binaryslack.slack.com.
- The announcements list
https://groups.google.com/group/binary_c-nucsyn-announce
This contains major announcements such as significant upgrades to binary_c (or the supporting software) - The development list
https://groups.google.com/group/binary_c-nucsyn-devel
This is more of a discussion list outlining specific changes to physics and technical development of the code(s).
1.5 Conventions¶
It is assumed you are using a bash shell and are familiar with the Linux/Unix command line (OSX is similar, see Sec. 4.7). Instructions which should be executed in a bash shells are preceded by $ symbols, which you should not type!, like this:Bash scripts look like this (with the the leading $ symbols which are not typed or saved),
cd $HOME
ls#!/bin/bash
# ...
# this is a bash script
export BINARY_C=$HOME/progs/stars/binary_c
cd $BINARY_C
./binary_c versionint x = 1;
x++;
printf("hello binary_c world x is %d\n",x);my $x = 1;
$x++;
print "hello binary_c world x is $x\n";Python code looks like this,
x = 1
x += 1
print(f"hello binary_c world x is {x}")top2 Quick start guide¶
This section is a quick guide to getting binary_c
and binary_c-python
to work. Please start reading at Section 3 if you want the full manual with complete installation instructions in Section 4.2.
2.1 Operating system requirements¶
2.1.1 Linux (Ubuntu 22.04) ¶
If you are running (say) Ubuntu, e.g. 22.04 or 24.04, the ubuntu_install_binary_c.sh script, in binary_c
’s root directory, will do the installation for you. Run the following to install even without a git account,
wget https://gitlab.com/binary_c/binary_c/-/raw/master/ubuntu_install_binary_c.sh
chmod +x ubuntu_install_binary_c.sh
./ubuntu_install_binary_c.shPlease see section
2.1.2 OSX¶
binary_c
has been tested on OSX Mavericks. You will need to install homebrew and the Gnu core utilities. Please see section 4.7 for more details.
2.1.3 Windows¶
binary_c
works in the Windows Subsystem for Linux (WSL).
2.2 Download and build binary_c ¶
In the following, I assume you have internet access. I also assume you are building for a generic 64-bit CPU on Linux, and have software like gcc, Perl5, Python3, wget and other standard build tools and system utilities installed. I assume your temporary directory is /tmp and you use a shell like bash. Installed support libraries will be put in $HOME/lib (with associated executables in $HOME/bin, include files in $HOME/include, etc.) so they are private to the user, rather than in system locations. binary_c
will be installed in the BINARY_C directory, usually $HOME/progs/stars/binary_c, and other software will be downloaded and built in $HOME/git.
Note: in the following I assume you want to use git with https. You might want to use SSH URLs instead, if you have set up (say) SSH keys on gitlab.com.
- Required (Do this once) Add to your .bashrc or equivalent shell profileand restart your shell so that the environment variable BINARY_C is defined.
export BINARY_C=$HOME/progs/stars/binary_c - Required (Do this once in .bashrc or manually every time) Set up LIBRARY_PATH, LD_LIBRARY_PATH and PATH in .bashrc. For example, add the following to .bashrc if you are using bash,and restart your shell.
export LD_LIBRARY_PATH=$HOME/lib:$BINARY_C/src export LIBRARY_PATH=$HOME/lib export PATH=$PATH:$HOME/.local/bin:$HOME/bin - Optional If you can, install libbsd – this is a system package so requires root access. You will require the development version which contains the various header files, this is usually called libbsd-dev (or similar). libbsd is not required for binary_c but is useful and may speed up the code.
- Probably required Update your meson and ninja,
pip3 install --upgrade meson pip3 install --upgrade ninja - Probably required If you can, install librinterpolate. binary_c
includes a version of librinterpolate as a backup, but it’s useful to build and install it so you get the latest version.
mkdir $HOME/lib $HOME/git cd $HOME/git git clone https://gitlab.com/rob.izzard/librinterpolate.git cd $HOME/git/librinterpolate meson setup --prefix=$HOME --buildtype=release builddir ninja -C builddir installNote: you must install librinterpolate if you want to install binary_c-python . - Optional If you can, install libmemoize. binary_c
includes a version of libmemoize as a backup, but it’s useful to build and install it so you get the latest version.
mkdir $HOME/lib $HOME/git cd $HOME/git git clone https://gitlab.com/rob.izzard/libmemoize.git cd $HOME/git/libmemoize meson setup --prefix=$HOME --buildtype=release builddir ninja -C builddir install - Optional If you can, install libcdict. binary_c
includes a version of libcdict as a backup, but it’s useful to build and install it so you get the latest version.
mkdir $HOME/lib $HOME/git cd $HOME/git git clone https://gitlab.com/rob.izzard/libcdict.git cd $HOME/git/libcdict meson setup builddir --prefix=$HOME --buildtype=release ninja -C builddir install - Required Clone the
branch of binary_c
.
export CC=gcc # or the compiler of your choice unset CFLAGS mkdir -p $HOME/progs/stars/ cd $HOME/progs/stars git clone https://gitlab.com/binary_c/binary_c.git - Required Change to the binary_c
directory, configure and build both binary_c
and its shared library. Note: if builddir already exists, you need to add
--reconfigureto the Meson command, or delete builddir before this step. Here we build a “release” version of binary_c with full optimization and no debugging support.binary_c is now installedcd $BINARY_C meson setup builddir --buildtype=release ninja -C builddir binary_c_install cd .. - Optional You can test binary_c
with binary_c-configwhich should tell you the binary_c version number.
cd $BINARY_C ./binary_c-config version - Optional If you want to use binary_c-python
to make stellar populations:
export GSL_DIR=`gsl-config --prefix` export LD_LIBRARY_PATH="$HOME/lib:$BINARY_C:$BINARY_C/src" # you may already have set this above export LIBRARY_PATH="$LD_LIBRARY_PATH" # you may already have set this above export PATH=$HOME/bin:$HOME/.local/bin:$PATH cd $HOME/git git clone https://gitlab.com/binary_c/binary_c-python.git cd binary_c-python ./install.sh
2.3 Running a single- or binary-star system: tbse¶
Go to the $BINARY_C directory and open the bash script tbse where tbse means “test binary-star evolution”.
- In this file you can set every physical parameter of binary_c
, for example the masses and orbital parameters
# stellar masses (solar units) M1=6 M2=0.9 # orbit: # If the period (days) is given, use it. # If the period is zero, use the separation (in Rsun) to calculate the period. # (this requires that the masses are already set) ORBITAL_PERIOD=0.0 ORBITAL_SEPARATION=3000.0 # Orbital eccentricity should be in the range 0.0-1.0. ECCENTRICITY=0.0 - You can also override physics by running tbse with subsequent command-line arguments, e.g., to run the default star with a metallicity of
:
tbse metallicity 0.004 - Do not run many stars this way because it will be really slow: use binary_c-python for such a task.
2.4 Running a grid of stars with binary_c-python ¶
- Open the file $BINARY_C/src/python/ensemble.py
- This is an example script that runs binary_c through binary_c-python to extract ensemble data from a grid of stars.
- You can change parameters in the file, which are set in Python dictionaries, or you can set these when you run the script on the command line.
- Try running the following:which runs a grid of stars, with some verbose output (to keep you updated every few seconds), a log-spaced grid in and saves the scalar and chemical-yield data to the ensemble in /tmp.
cd $BINARY_C ./src/python/ensemble.py r=10 verbosity=1 M1spacing=logM1 ensemble_filter_SCALARS=1 outdir=/tmp
top3 Introduction¶
For many years the study of stellar yields and galactic chemical evolution (GCE) has gone on assuming, mainly for simplicity, that stars are isolated objects (one exception being , 2002). Reality bites deeply into this picture with the observation that most stars are in multiple systems and that many of these systems are interacting. The state of the art in binary star nucleosynthesis is focused on explosive events such as type Ia supernovae and classical novae but other binary star processes contribute to pollution of the interstellar medium. Mass-transfer by Roche-lobe overflow (RLOF) occurs particularly when the stellar radius is growing rapidly and so commonly when one star is on the asymptotic giant branch (AGB).
To investigate the effect of a companion on stellar nucleosynthesis the binary_c
code was developed. The binary_c
code currently uses the SSE/BSE package at its core to provide most of the stellar evolution modeling, with nucleosynthesis in parallel based on various algorithms, to explore the large parameter spaces associated with binary stars in reasonable periods of time. Binaries are important for nucleosynthesis because of two main effects:
- The presence of a companion affects evolution by mass loss and gain. Good examples are Roche-lobe overflow caused by interaction between a giant branch or asymptotic giant branch (GB/AGB) star and a main-sequence (MS) star. Truncation of the GB/AGB phase may prevent dredge-up events and hence reduce the amount of nuclear processing material undergoes prior to expulsion to the ISM. Common envelopes generally result and while the detailed physics is unclear it is likely that mass is ejected to the ISM from some of these stars.
- Novae, type Ia supernoave, X-ray bursts, stellar mergers (including neutron-star/black-hole mergers), etc. occur in binaries, as do many tidal disruption events. These may eject material or lead to extra nuclear burning.
The physics of binary evolution is not all that well understood and, at the same time, suffers all the uncertainties of single-star evolution. Some effects which must be considered are:
- Duplicity: is the star single or binary or perhaps even triple or quadruple?
- Metallicity and, less importantly, initial abundance mix. The initial abundance mix depends on the galactic evolution history and even the solar mixture is somewhat uncertain.
- Initial distributions: What is the IMF? What is the initial distribution for primary mass, secondary mass, separation/period and eccentricity in binary stars?
- Abundance changes at dredge-ups. These changes can depend on the input physics, especially in the case of third dredge-up. Calibration to observations is necessary in this case and leads to the introduction of free parameters to increase the amount of dredge-up. There is also great uncertainty with regard to the s-process isotopes, in particular the size of the C13 pocket during third dredge-up.
- Wind loss rates. Mass loss due to stellar winds is a very dodgy affair - most prescriptions in current use are quite phenomenological and have little regard for actual physics. With this in mind it is important to test a range of prescriptions.
- Common envelope parameters - the parameters and parameterise our ignorance of this complex process, mainly because the mechanism for driving off the stellar envelope is unclear (magnetic fields? friction? ionization? who knows!). This problem is very much open (, 2012; , 2013).
- Eddington limit : should this be imposed during accretion processes?
- HBB temperature : somewhat uncertain is the amount of HBB, this can be varied in the model
- Black hole formation : what is the mass of a black hole forming from a given mass progenitor?
- Supernova kicks : is there a kick at SN formation? What is the magnitude/distribution of this kick? Pulsar peculiar velocities give us an idea but are not necessarily the answer to the question.
- Binary induced wind loss (Companion Reinforced Attrition Process - CRAP) - see Chris Tout’s PhD. Does the presence of a binary companion increase wind loss rates? What about circularization? (Barium stars are eccentric and have short periods – current theory, and this code, cannot make these stars!)
- Time evolution of the yields. Even if the integrated yield up to (say) 15Gyr from a population of stars is similar when comparing binary and single stars, the time evolution probably is not. For example, nitrogen peaks far more quickly in single than in binary stars because massive ( ) TPAGB stars in binaries overflow their Roche lobes prior to HBB so C12 cannot be converted into N14.
- Numerical resolution - requires careful consideration!
binary_c
is the trade name for the C-version of the Binary Star Evolution (BSE) code of (2002) with added nucleosynthesis. The nucleosynthesis algorithm runs (mostly) in parallel to the nucleosynthesis code and includes the following (see , 2006b; , 2009; , 2018; , 2022 and many subsequent papers):
- First and second dredge-up fitted to the detailed nucleosynthesis models of (2002).
- A new synthetic model of TPAGB stars (, 2004) in collaboration with Amanda Karakas, Chris Tout and Onno Pols based on the Karakas et al. models. The effects of third dredge-up, the -process, hot-bottom burning (CNO, NeNa and MgAl) and mass loss are included.
- Phenomenological fits to massive and Wolf-Rayet star surface abundances (elemental H, He, CNO, Ne) based on the models of Lynnette Dray (, 2003). These were recently complemented by tables from Richard Stancliffe which include all the isotopes up to iron (Stancliffe, private communication, see also , 2006a).
- Supernovae: types Ia, II and Ib/c with yields fitted to published models (, 1986; , 1995; , 1995; , 1999; , 2004).
- Nova yields fitted to (1998).
- -process “yields” (I say this in the loosest possible sense!) from Arlandini et al 1999 and Simmerer 2004.
- Roche-Lobe Overflow and (possible) accretion onto the companion, common-envelope loss contribution to yields.
- Mass loss due to winds and mass gain from a companion.
- Colliding winds.
- Accretion is treated with a two-layer model and thermohaline mixing.
- Mergers.
- SN stripping of companions.
- Planetary orbits.
- Circumbinary discs (, 2022).
- (With MINT) MS burning of the interior of the star and stellar structure lookup tables.
What does the binary_c
code not do?
- Diffusion - nobody plans to work on this!
- "Extra mixing" - dubious although might be the cause of J-stars.
- Common envelope nucleosynthesis - thought not to be important, but you never know.
- WD surface layers - these are very complicated!
- Stellar structure changes caused by rotation. Tricky one this! Not only is the rate of rotational mixing unknown, few stars are thought to rotate this fast. But… these should be included, so let me know if you know a way.
- Probably some other things too.
3.1 Binary_c : tools for stellar evolution and population synthesis¶
The binary_c
software framework consists of a number of tools, in particular:
- binary_c
- The binary_c code itself. This is the core code, written in C, which contains the stellar evolution and nucleosynthesis algorithms.
- libbinary_c
- The shared library based on binary_c which should be accessed through the binary_c API functions. This works with other languages such as Python and FORTRAN.
- binary_c-python
- A suite of software to run many stars in a stellar population. If you want to run more than a few stars at once, and combine the results into something useful for science, this is the tool you should use.
top4 Installation¶
The following is an installation guide for installing binary_c
and some of its support tools. If you know how to run code, and want to run binary_c
as quickly as possible, just go for the quick start guide. If you want to get binary_c
, either as source code, a virtual machine or Docker image, see section 4.2. Technical system requirements are discussed in section 4.3. Building binary_c
is described in section 4.5.
By using binary_c
and binary_c-python
you are part of a community. You are therefore jointly responsible for helping with the never-ending process of improvement and bug fixing. Binary_c
and binary_c-python
are stored on a git server. Please read the LICENCE file before use.
4.1 Quick start¶
See Sec. 2 for a quick start guide.
4.2 Getting binary_c ¶
You can either get the binary_c
source code and build it yourself, or use the prebuilt Docker image. Please note that only the source code gives you the latest version.
4.2.1 Getting the binary_c source code¶
You have a choice whether to use either
- the latest stable release or
- the latest version in the master branch.
The stable release is likely to contain all that you need unless you require some bleeding edge changes.
- With git
- download the source code from https://gitlab.com/binary_c/binary_c, e.g. from the command line,or, if you have set up SSH keys on gitlab.com,
git clone https://gitlab.com/binary_c/binary_c.gitIf you then want to change to the latest release, you should change to the appropriate branch, e.g.git clone git@gitlab.com:binary_c/binary_c.git
git checkout releases/2.2.3 - As a zip file
- You should get the master if you can from https://gitlab.com/binary_c/binary_c/-/archive/master/binary_c-master.zip
or you can either download a release, e.g.,
https://gitlab.com/binary_c/binary_c/-/archive/releases/2.2.3/binary_c-releases-2.2.3.zip
Note that you can change.zipto.tar.bz2or.tar.gzshould you prefer a different compression algorithm.
4.2.2 Editing the source code¶
At present, the binary_c
source code is accessed through gitlab.com at https://gitlab.com/binary_c. You need a gitlab.com account to commit code.
4.2.3 Getting the Docker image¶
You can access binary_c
through docker. Please note that this may be outdated compared to the current version of binary_c
: please chase Rob if you want the Docker version updated.
- I assume you have installed and signed in to docker. I cannot provide support for Docker!
- The newest binary_c
container should be used. At the time of writing this is robizzard/binary_c:master2.2.3
Public URL at Docker: https://hub.docker.com/r/robizzard/binary_c - Pull the “latest” version withor a specific version (in this case 2.2.3) with
docker pull robizzard/binary_cdocker pull robizzard/binary_c:master2.2.3 - When you run Docker it inherits your stack settings, which may be too small for binary_c to run. Use in your startup command to avoid this.
--ulimit stack:-1 - Run it with a command likethis loads a bash shell in the directory of binary_c .
docker run --ulimit stack=-1 -it robizzard/binary_c:latest /bin/bash --login - Further information can be found in the file
/home/binary_c/progs/stars/binary_c/doc/README.docker - The following bash script allows you to run an X11-enabled terminal with binary_c
and binary_grid
prebuilt, you have to do nothing more than run them.
#!/bin/bash ############################################################ # run binary_c using docker on Linux/Unix ############################################################ ############################################################ # we create a volume in binary_c_persistent : this # is a persistent file space that is stored even when # binary_c stops ############################################################ docker volume create binary_c_volume >/dev/null ############################################################ # Allow connections to our X display ############################################################ XAUTH=$(mktemp) xauth nlist $DISPLAY | sed -e 's/^..../ffff/' | xauth -f $XAUTH nmerge - chmod 755 $XAUTH ############################################################ # run a bash login shell in the container : # this leaves us in an X-connected shell. # # Note the chown/chgrp to make the persistent directory # writable by the user "binary_c" ############################################################ docker run \ --name=binary_c \ -it \ --rm \ -e DISPLAY=$DISPLAY \ --ipc=host \ --net=host \ --mount source=binary_c_volume,target=/home/binary_c/binary_c_persistent \ -v /tmp/.X11-unix \ -v $XAUTH \ -v $HOME/.Xauthority:/home/binary_c/.Xauthority \ robizzard/binary_c:master2.2.3 \ /bin/bash -c "sudo chown binary_c binary_c_persistent ; sudo chgrp binary_c binary_c_persistent; cat /home/binary_c/progs/stars/binary_c/doc/README.docker; bash --login" # to clean the BINARY_C volume run: # docker volume rm binary_c_volume # clean up XAUTH rm $XAUTH
4.3 System Requirements¶
In the following I assume you are using a Linux-type system (e.g running an distribution like Ubuntu). If you are not, I highly recommend using a virtual machine (e.g. Virtualbox) to run Linux on your system. MacOSX and Windows have a quite different build structure compared to Linux, please see Section 4.7 for OSX-specific advice. You can also run the Docker directly on MacOSX and Windows.
- Linux-specific requirements are listed in Sec. 4.6.
- OSX-specific requirements are listed in Sec. 4.7.
- Windows-specific requirements are listed in Sec. 4.8.
4.3.1 C compiler¶
A C compiler is required, e.g. one of,
- GCC (the GNU compiler http://gcc.gnu.org/) this comes as standard on most Linux and MacOSX systems and is easily installed on others, and is free software.
- Clang (C compiler for LLVM http://clang.llvm.org/) is also free, and may be faster than gcc.
- icc (Intel compiler http://software.intel.com/en-us/articles/intel-compilers/) this costs money but it is probably faster than gcc. Please note, I do not have a copy of icc and building with it is likely to be very slow.
Your system should include such a compiler unless you’re using Windows. Binary_c
has been tested on Linux, Solaris (albeit a long time ago!), Windows (using Windows Subsystem for Linux) and MacOSX.
Your C compiler should support the __VA_OPT__ macro, which is being implemented in the C23 standard. At the time of writing, binary_c
thus requires GCC version 8 or later, or Clang version 12 or later.
4.3.2 Scripting language(s)¶
- Python should be installed on your system, please use version 3.8 or later. You will also probably need pip.
- Perl is usually installed on your system, or you can download Perl at www.perl.com. If you want to install your own Perl I recommend Perlbrew. Please try to use a version of Perl that is 5.16 or later: 5.37.5 is currently the latest version and works just fine.
4.3.3 Build tools¶
Standard build tools and system commands, such as make, tr, sed, head, tail, cd, which, grep, gawk, cp, ln, wc, env, ls, rm, objdump and objcopy. I will also assume you are using the bash shell. These are all available as system packages in Linux and other Unix variants, such as MacOSX (please install the GNU core utils and see Section 4.7), e.g. the coreutils, binutils, bash and build-essential packages on Ubuntu.
You should install meson and ninja. You can install these tools on your system, or follow installation instructions at https://mesonbuild.com/Getting-meson.html. You should make sure you have meson V0.52.0 or later. If you have Python3 and pip installed, you can get the latest versions of meson and ninja with,or, if these modules are already installed,Note: emacs users should install the meson-mode. Go to https://github.com/wentasah/meson-mode and download meson-mode.el to your ~/.emacs-el directory. In your ~/.emacs file add the following.You can edit the meson-mode.el to suit your needs: I changed the indentation from 2 to 4, for example, to match other modes.
pip3 install meson
pip3 install ninjapip3 install --upgrade meson
pip3 install --upgrade ninja ; meson support
(load "~/.emacs-el/meson-mode.el")4.4 Software libraries¶
You should make sure Meson knows about the locations of your software libraries should you choose to use them.
4.4.1 Library locations¶
Meson will know where to find libraries installed as part of your system, e.g. with apt. However, it cannot know where you have put libraries that you have installed from source or in some other way. Usually it is sufficient to set their locations, i.e. the directories in which they reside, in the environment variables LIBRARY_PATH (for compilation) and LD_LIBRARY_PATH (at runtime, or DYLD_LIBRARY_PATH on OSX). For example, to point to the directories $HOME/lib and $HOME/otherlibs, using bash,
export LIBRARY_PATH=$HOME/lib:$HOME/otherlibs
export LD_LIBRARY_PATH=$HOME/lib:$HOME/otherlibsbinary_c
(optionally) uses libmemoize, librinterpolate and libcdict, written by RGI. These should really just be installed locally, but there are internal versions of these inside binary_c
just in case you cannot install them.
- If you are using a non-system GSL, and have a system GSL installed at the same time, you need to make sure the location of the non-system gsl-config is first in your PATH. Try runningand this should, if you have installed GSL in /home/user (which is what is in $HOME), give you something like
gsl-config --cflagsotherwise you should do something like-I/home/user/includeto force $HOME/bin/gsl-config to run first.export PATH=$HOME/bin:$PATH - If you are using a locally-installed libcfitsio you will need to point pkgconfig to the right place. If you installed with
prefix=$HOMEyou should do:export PKG_CONFIG_PATH=$HOME/lib/pkgconfig
4.4.2 Required libraries¶
- Required Install librinterpolate. This is optional for binary_c
, but required for binary_c-python
.
export PREFIX=$HOME mkdir $HOME/lib $HOME/git cd $HOME/git git clone https://gitlab.com/rob.izzard/librinterpolate.git cd $HOME/git/librinterpolate meson setup builddir --prefix=$HOME --buildtype release cd builddir ninja install
4.4.3 Recommended libraries¶
You should install the latest versions of support libraries, e.g. libcdict, libmemoize and librinterpolate, directory from their gitlab repositories. If you do not, binary_c
has an internal version as a backup but this may out of date.
- Optional If you plan to modify binary_c you probably want a debugger of some sort. On Linux Valgrind and gdb are both excellent, the former for detecting memory leaks and the latter for backtracing, but both are very powerful and flexible tools. You can run binary_c through both using tbse (e.g. Sec. 13.7).
- Optional You could use ccache to speed up builds. You can usually install this as a system package, or see the ccache homepage.
- Optional If you can, install libmemoize. If you do not, binary_c
has an internal version but this may out of date.
export PREFIX=$HOME mkdir $HOME/lib $HOME/git cd $HOME/git git clone https://gitlab.com/rob.izzard/libmemoize.git cd $HOME/git/libmemoize meson setup builddir --prefix=$HOME --buildtype release cd builddir ninja install - Optional If you can, install libcdict (this requires meson and ninja). If you do not, binary_c
has an internal version but this may out of date.
export CFLAGS="-O3 -mtune=generic" mkdir $HOME/git cd $HOME/git git clone https://gitlab.com/rob.izzard/libcdict.git cd $HOME/git/libcdict meson setup builddir --prefix=$HOME --buildtype release cd builddir ninja install
4.5 Configuring and building binary_c ¶
4.5.1 From git¶
4.5.2 From a zip file or tarball¶
If have been given a file zip file binary_c.zip, or a tarball e.g. binary_c.tar.gz or binary_c.tar.bz2, you should copy it to a directory (hereafter binary_c, usually I put everything in
/progs/stars/binary_c where
is your home directory – if you put it there then all the scripts will work) and unzip it with one of the following commands (depending on the type of file you were given):
unzip binary_c.zip
tar -xvf binary_c.tar.gz
tar -xvf binary_c.tar.bz2which will unzip the files in the appropriate places.
4.5.3 Set up ccache (optional)¶
If you have ccache installed, you will need to set it up so that it works with precompiled headers. To do this, run the following command.
ccache --set-config=sloppiness=pch_defines,time_macrosAlternatively, if you are using bash as your shell and ccache is installed in binary_c (the standard location in Ubuntu Linux, put the following in your .bashrc to have ccache always behave as you wish.
# use ccache if available
if [[ -d /usr/lib/ccache ]]; then
export PATH=/usr/lib/ccache/:$PATH
export CCACHE_SLOPPINESS=pch_defines,time_macros
fi4.5.4 Building with Meson¶
Now, from the binary_c directory, you need to use Meson to makeor for a release build (with full optimization),see Sec. 4.5.5 for more information on buildtypes. Now you should go to the builddir directory to and run ninja (see sections 13.19 and 13.20 for meson- and ninja-bash autocompletion instructions).
2
a build directory, e.g., for a normal development build (without full optimization),Consider installing also ccache and bash auto-completion for Meson.
meson setup builddirmeson setup builddir --buildtype releasecd builddir
ninja binary_c_installThe executable is called binary_c. To run a star go back to the main binary_c
directory and run tbse to launch this, e.g.,
cd ..
./tbseor run binary_c
directly, e.g.,
cd ..
./binary_c M_1 10 max_evolution_time 1000 log_filename /dev/stdoutNote: binary_c is built as a single, possibly large (many MB) executable. The reason for this is the ease of use when transferring the executable from one machine to another (e.g. for use with distributed computing). It is possible to build a shared library instead (see below) and future binary_c
versions will use environment variables to point to data directories (the
library already does this).
4.5.5 Meson buildtypes¶
Meson takes an argument buildtype which changes whether the build is for development (i.e. a debug build), testing or for software release. For example, to build for release – which is what you often want because this is as optimized, hence as fast, as possible – run:
meson setup builddir --buildtype releaseYou can change the buildtype to debug if you want to build for testing: this is the default if you do not include any buildtype argument.
meson setup builddir --buildtype debugThe full list of buildtypes is plain, debug, debugoptimized, release and minsize with details at https://mesonbuild.com/Running-Meson.html.
4.5.6 Cleaning the build tree¶
You can clean the build directory with
cd builddir
ninja clean4.5.7 Building the shared library libbinary_c ¶
To build the shared library only, go back into the builddir and run,
cd builddir
ninja libbinary_c.soThis makes the libbinary_c.so shared library which can be used, for example, by binary_c-python
or to access binary_c
through its API functions.
4.5.8 Building binary_c and libbinary_c , and installing them for binary_c-python ¶
You can build and install both binary_c
and libbinary_c
in locations which are compatible with legacy builds and binary_c-python
with one command:
cd builddir
ninja binary_c_installAfter doing the above, you can remove the builddir completely.
4.5.9 Alternative compiler¶
You can build with another compiler, e.g. clang, by setting the CC environment variable. If you have not yet made a builddir, do the following.
export CC=clang
meson setup builddir --buildtype release
cd builddir
ninja binary_c_install4.5.10 Existing builddir¶
If you already have a builddir, instead of deleting it, do the following,
export CC=clang
cd builddir
meson --reconfigure --buildtype release
ninja binary_c_install4.5.11 Debugging build¶
To enable full debugging, run, from within builddir,or just because debug is the default buildtype. You require debugging to use gdb, valgrind, etc.
meson setup builddir -Dvalgrind=true --buildtype debug
ninja binary_c_installmeson setup builddir
cd builddir
ninja binary_c_installMany GCC installations include libbacktrace. If meson is telling you it is missing, you might want to install it from the code at https://github.com/ianlancetaylor/libbacktrace. Problems have been reported with the libbacktrace static library on Windows Subsystem for Linux because it is not compiled with -fPIC. This is not a binary_c
bug.
4.5.12 Valgrind build¶
The extra meson setup flag -Dvalgrind=true is required on some newer CPUs because the CPU contains instructions which are unknown to the latest version of Valgrind. As of binary_c
2.2.0 you are required to use -Dvalgrind=true if you want to run binary_c
through Valgrind.
4.5.13 Accurate floating point build¶
Binary_c
generally does not require perfect floating-point accuracy and uses -ffast-math for extra speed, but you can turn on gcc’s various flags to improve accuracy with
meson setup builddir -Daccurate=true4.5.14 Generic build, e.g. for HTCondor or Slurm clusters¶
You may wish to build a generic version of binary_c
which is not tied to the CPU architecture or operating system on which you are building, e.g. if your binary_c
is required for use on the many machines of an HTCondor or Slurm grid. Try
meson setup builddir -Dgeneric=trueNote: we do our best to make an executable run on a different CPU in the same architecture (e.g. x86_64). If you really want this to work, you also need to compile on the machine with the oldest glibc.
4.5.15 Extended API build¶
If you want to build the extended API, so you have access to every function in binary_c through its shared library, use
meson setup builddir -Dextended_API=truePlease see section 8 for more details.
4.5.16 Extra libraries¶
A number of external libraries can be used, particularly during debugging. These include libiberty, libbfd (part of GCC) and (if it does not come with your GCC) libbacktrace. The latter is particularly useful, and I recommend installing it if you want to do any serious debugging. You can download libbacktrace from https://github.com/ianlancetaylor/libbacktrace.
4.5.17 Profile-guided builds¶
Some compilers, e.g. GCC and clang, allow for profile-guided optimization (PGO). binary_c
has a script that wraps meson and ninja to allow you to do this, and test speed increases, automatically. Run, from the binary_c
root directory, to do this. This builds with PGO, running binary_c
N times to test the speed increase. You can pass an integer value for N as the first argument of the script – more stars is more accurate, but takes longer.
./meson/pgo.shIf you want to build yourself, do something like the following
meson setup -Db_pgo=generate --wipe builddir
ninja -C builddir binary_c_install
tbse random_systems true repeat 100 # run some test systems
meson setup -Db_pgo=use --reconfigure builddir
ninja -C builddir binary_c_install
# now you have a profile-guided executable, ./binary_c4.5.18 Link-time optimization¶
You can enable link-time optimization with
meson -Db_lto=true setup builddir4.5.19 Troubleshooting¶
- If you see compilation errors like you need to disable Address Space Layout Randomization (ASLR), see e.g. https://askubuntu.com/questions/318315/how-can-i-temporarily-disable-aslr-address-space-layout-randomization or run
text segment at different address(note: this requires root access)echo 0 | sudo tee /proc/sys/kernel/randomize_va_space
4.6 binary_c on Linux ¶
The above instructions generally assume a Linux-compatible system and, if you are running Ubuntu or similar, you can install with ubuntu_install_binary_c.sh. However, should you require them, you can install the following packages by hand (where gcc-12, python3.10 etc. might be later versions for you).
binutils binutils-dev coreutils debianutils bash zip gcc-12 libgcc-12-dev gdb valgrind gawk python3.10 pipenv kcachegrind meson ninja-build emacs perl libgsl-dev libgslcblas0 global libbsd-dev libiberty-dev libjemalloc-dev zlib1g zlib1g-dev unzip wget curl git jp2a libcfitsio-dev sed gawk pkg-config libc6 libc6-dev patchelf uuid-dev pandoc libgpg-error-dev libgpgme-dev swig libcairo2-dev libgirepository1.0-dev autoconf python-dev python3-dev zlib1g-dev You might also need to switch to using the latest Python, e.g. to switch to 3.10,
sudo update-alternatives --install /usr/bin/python python /usr/bin/python3.10 14.7 binary_c on MacOSX¶
To run binary_c
on OSX first you should install the GNU core utilities, e.g. using homebrew. Then, set up your path to include the GNU utilities, e.g. with Now, meson and ninja should work just as on Linux. You should be able to run tbse to test that one star runs.
export PATH=/usr/local/opt/coreutils/libexec/gnubin/:/usr/local/bin:$PATHPlease note: OSX changes regularly, and often new “security” features break everything. This is not our fault! You may well need to understand basics of Unix and e.g. bash, compilation steps, how to report errors effectively and debugging, to make everything work. We can provide support, but every version of OSX is different so it’s not easy.
Massimiliano Matteuzzi suggests setting the following in your .zprofile or .bashrc.
export PREFIX=$HOME/software_sci #THAT IS THE DIRECTORY IN WHICH I PUT BINARY_C (I.E. THE PREFIX USED FOR MESON)
export CC=$(which clang)
export LDFLAGS="-L/opt/homebrew/opt/llvm/lib" #NEEDED IN MACOSX
export CPPFLAGS="-I/opt/homebrew/opt/llvm/include" #NEEDED IN MACOSX
export BINARY_C=$HOME/software_sci/binary_c
export LIBRARY_PATH=$HOME/software_sci/lib:$BINARY_C/src:$BINARY_C
export LIBRARY_PATH=$LIBRARY_PATH:/opt/homebrew/Cellar/cfitsio/4.1.0/lib #ADDED IN ORDER TO LET THE MACOSX UNDERSTAND WHERE CFITSIO IS LOCATED
export LD_LIBRARY_PATH=$LIBRARY_PATH
export DYLD_FALLBACK_LIBRARY_PATH=$LIBRARY_PATH #NEEDED IN MACOSX
export GSL_DIR='gsl-config --pref'
export PATH=$PATH:$HOME/software_sci/bin:$HOME/.local/bin
export PATH="/opt/homebrew/opt/llvm/bin:$PATH" #NEEDED IN MACOSX
export PATH=/opt/homebrew/opt/coreutils/libexec/gnubin:$PATH #NEEDED IN MACOSX4.8 binary_c on Windows ¶
4.9 binary_c on VirtualBox¶
You can install binary_c
very quickly on Virtualbox using the Ubuntu install script. The following list of instructions works for me, at the time of writing, using Ubuntu 22.04.
- Download and install VirtualBox from https://www.virtualbox.org/. You need to install VirtualBox and the VirtualBox extensions pack.
- Download the Ubuntu image from https://releases.ubuntu.com/. The current 22.04 image is at https://releases.ubuntu.com/22.04/.
- Run VirtualBox and go to Machine->New, where you have to enter a name for the machine and various other things like a user name and password. I assume both the user and password are set to binary_c.
- You should select as much RAM and CPU power as you can spare. Usually you require 20-25GB of disk space, at least. Most importantly, select the ISO image to be the Ubuntu image you downloaded just now. Start the installation by clicking Next repeatedly, filling in the boxes as you see fit.
- The installation takes a little while, but when it is done log in to the new virtual machine (VM) using the name and password you chose. Once your desktop loads, click “Show applications”, the grid icon in the bottom-left corner, and then choose the Terminal. In the terminal run
to become super user, using your chosen password. Now put your user (I assume you are binary_c) in the sudoers list and exit “super-user mode”.suadduser binary_c sudo exit
- Restart the virtual machine, then log in and run the terminal again.
- In the VirtualBox menu click Devices -> Insert Guest Additions CD image
- In the terminal, run
cd /media/binary_c/VBox_GAs_7.0.2 sudo ./VBoxLinuxAdditions.run - Wait for the installation to finish, log out and restart the virtual machine, and re-enter the terminal
- In the VirtualBox menu, click Devices->Shared Clipboard->Bidirectional so you can copy paste the following commands into the terminal
- Run and follow the on-screen prompts to install binary_c , support libraries and binary_c-python . When asked how to install binary_c , use the https option unless you have set up SSH keys (probably you haven’t).
wget https://gitlab.com/binary_c/binary_c/-/raw/master/ubuntu_install_binary_c.sh chmod +x ubuntu_install_binary_c.sh ./ubuntu_install_binary_c.sh - If there are errors installing binary_c-python
, try opening a new terminal and then
cd git/binary_c-python ./install.sh
top5 Evolving single and binary stars¶
This section describes how to run binary_c
on one stellar system, be it single or binary. The web home of binary_c
is https://binary_c.gitlab.io/. The online binary-star simulator is at http://personal.ph.surrey.ac.uk/~ri0005/cgi-bin/binary5.cgi. If these should move, you can use your favourite web-search engine to locate the code.
You should consider joining the mailing lists (see Sec. 1.4).
5.1 Running one star with “test binary star evolution”: tbse¶
A bash script called tbse is provided to run one single or binary star system. Run it with
./tbsefrom the binary_c
directory (you can omit the . if it is in your PATH). The script sets a number of bash variables (in capital letters) which are then passed to binary_c
. In general, the capitalized bash variable corresponds to the same variable in binary_c
in lower case. For example,
# Initial primary mass
M1=6
# Initial secondary mass
M2=3
# Initial orbital period (days)
ORBITAL_PERIOD=100
# Initial eccentricity
ECCENTRICITY=0.2
# (Initial) Metallicity
METALLICITY=0.02
# Maximum evolution time (MYr)
MAX_EVOLUTION_TIME=16000Many parameters are not just simple floating-point numbers, they are choices of algorithms. You can replace the numerical algorithm number, as usually defined by a macro in a header file, with the macro itself. For example, the following two are equivalent because the macro MAGNETIC_BRAKING_ALGORITHM_HURLEY_2002 is defined to be 0,similarly, you can use True and False (or t, T, true, etc.) to represent 1 and 0 respectively when setting boolean options,
MAGNETIC_BRAKING_ALGORITHM=0
MAGNETIC_BRAKING_ALGORITHM=MAGNETIC_BRAKING_ALGORITHM_HURLEY_2002PRE_MAIN_SEQUENCE=True
PRE_MAIN_SEQUENCE_FIT_LOBES=FalseA simple output log is sent to the file defined in LOG_FILENAME which is /tmp/c_log2.out by default.
LOG_FILENAME=”/tmp/c_log2.out”What gets output to the screen depends on what options you select and what logging you put in (see section 10).
Usefor general binary_c
help, or to get help on the contents of string, for example let’s say you want to know which options are available for the magnetic_braking_algorithm preference:
./binary_c help ./binary_c help <string>$ ./binary_c help magnetic_braking_algorithm
binary_c help for variable : magnetic_braking_algorithm <Integer>
Algorithm for the magnetic braking angular momentum loss rate. 0 = Hurley et al. 2002, 1 = Andronov, Pinnsonneault and Sills 2003, 2 = Barnes and Kim 2010, 3 = Rappaport 1983
Available macros:
MAGNETIC_BRAKING_ALGORITHM_HURLEY_2002 = 0
MAGNETIC_BRAKING_ALGORITHM_ANDRONOV_2003 = 1
MAGNETIC_BRAKING_ALGORITHM_BARNES_2010 = 2
MAGNETIC_BRAKING_ALGORITHM_RAPPAPORT_1983 = 3
Do not use tbse to run many stars in a stellar population! This is amazingly inefficient: you’ll waste a huge amount of time just loading bash and saving your data.
5.2 tbse commands¶
tbse can take extra arguments, which are often passed to binary_c
directly or are directives to perform special tasks.
- tbse echo
- This outputs (to stdout) the arguments that would have been sent to binary_c.
- tbse_echolines
- As tbse echo but in a single line of output. Newlines are converted to \n.
- tbse args
- Ignores settings in the tbse file and runs only with the extra arguments given on the command line.
- tbse arglines
- As tbse args but in a single line of output. Newlines are converted to \n.
- tbse debug
- This runs binary_c with the gdb debugger
- tbse gdb
- This runs binary_c with the gdb debugger
- tbse valgrind
- This runs binary_c through Valgrind’s memcheck tool to detect memory leaks. Remember to use the flag -Dvalgrind=true when running meson.
- tbse valgrind_args
- This shows the command-line arguments that are passed to Valgrind and then exits.
- tbse massif
- This runs binary_c through Valgrind’s massif heap checker.
- tbse callgrind
- This runs binary_c through Valgrind’s callgrind tool. Hint: process the output through kcachegrind.
- tbse cachegrind
- This runs binary_c through Valgrind’s cachegrind tool.
- tbse ptrcheck
- This runs binary_c through Valgrind’s ptrcheck tool (note: this tool no longer seems to exist).
- tbse sgcheck
- This runs binary_c through Valgrind’s sgcheck tool (note: this tool no longer seems to exist).
- tbse drd
- This runs binary_c through Valgrind’s drd tool.
- tbse gprof
- This runs binary_c through gprof, the GNU profiler.
- tbse gprof_lines
- This runs binary_c through gprof, the GNU profiler, doing line-by-line accounting.
- tbse gprof_with_stdout
- This runs binary_c through gprof, the GNU profiler, showing stdout.
- tbse pgo
- Profile guided optimization. This option is deprecated. Please use the meson/pgo.sh script instead.
- tbse bug
- This runs binary_c and outputs information which is suitable for reporting a bug to Rob.
- tbse multicore
- This runs binary_c on many CPU cores at once. Exits immediately on failure, so this is useful for testing e.g. Monte carlo kicks.
- tbse multicore_valgrind
- As tbse_multicore but using Valgrind.
- tbse <filename>
- This runs the set of arguments specified in the file given by filename.
- tbse clip
- Runs binary_c and saves the output to the clipboard (requires xclip).
5.2.1 Testing many (random) systems¶
Sometimes the best thing to do is test many random systems. You can do this with the test_random.pl script. I usually run it with something like:where the options are
cd $BINARY_C
nice -n +19 ./src/perl/scripts2/test_random.pl threads=cpu newlogs logtimes updatetime=0.25 sleeptime=0.25 valgrind- nice -n +19
- to make sure we only use idle CPU cycles
- threads=cpu
- this uses threads, where is the number of CPU cores (thus leaves one for managing the runs)
- newlogs
- Makes a new log file in $HOME/binary_c_test_random.log
- logtimes
- Makes a file $HOME/binary_c_test_random.logtimes containing data that tells us how long each system takes to run
- updatetime=0.25
- Number of seconds between updating the screen
- sleeptime=0.25
- Internal sleep time before checking things
- valgrind
- Run binary_c through valgrind (warning will be slow, but thorough)
top6 Making populations of stars with binary_c-python ¶
Many Python notebooks are provided at
You can read the JOSS paper at
top7 The binary_c ensemble¶
This section describes the binary_c
population ensemble output. This is a standard method by which you can access a statistical description of a stellar population in the popular JSON format, suitable for fast import into third-party tools and other programming languages.
7.1 The population ensemble ¶
From version 2.17, binary_c
has a standard output form, the population ensemble. The ensemble is built as an associative array, using a hash table, known as a “hash” in Perl and “dictionary” in Python, using the libcdict library.
7.2 Building binary_c with the ensemble¶
Usually the ensemble is built in, but is turned off by default. The following are set in binary_c_parameters.h:
#define STELLAR_POPULATIONS_ENSEMBLE
#define STELLAR_POPULATIONS_ENSEMBLE_SPARSE
#define STELLAR_POPULATIONS_ENSEMBLE_ND
#define STELLAR_POPULATIONS_ENSEMBLE_DEFAULT FALSE
#define STELLAR_POPULATIONS_ENSEMBLE_DEFER_DEFAULT FALSE
#define STELLAR_POPULATIONS_ENSEMBLE_LOGTIMES_DEFAULT FALSE
#define STELLAR_POPULATIONS_ENSEMBLE_DT_DEFAULT 1.0
#define STELLAR_POPULATIONS_ENSEMBLE_LOGDT_DEFAULT 0.1
#define STELLAR_POPULATIONS_ENSEMBLE_STARTLOGTIME_DEFAULT 0.17.3 Enabling ensemble output¶
You can turn on the ensemble using the Boolean argument ensemble or by setting
stardata->preferences->ensemble, e.g.,
stardata->preferences->ensemble, e.g.,
./binary_c ... ensemble True- Remember True can also be TRUE, T, t or 1, while False can also be FALSE, F, f or 0.
7.3.1 Finer control of ensemble output¶
The full ensemble is a lot of data, so you have options to filter which output is constructed and output. A list of filters is in where the index is defined in X-macros in src/ensemble/ensemble_macros.def. You can obtain a list of these withBy default, these are set to TRUE which means there is a lot of output. You may want to be more selective, otherwise – particularly if you are multithreading – you will require a lot of system memory.
stardata->preferences->ensemble_filters[ENSEMBLE_FILTER_NUMBER_OF_FILTERS]./binary_c version |grep ’Ensemble filter’- To disable all sections of the ensemble, use
ensemble_filters_off True - To then turn on some of the filters, use, e.g.,
ensemble_filter_ORBIT True - If you only want to turn off one filter, do not use ensemble_filters_off, instead set the filter to FALSE, e.g.,
ensemble_filter_MERGED False - Note that the final part of ensemble_filter_MERGED can be either a macro, as
#definedabove, or the corresponding index. For example, these are identical,ensemble_filter_ORBIT Trueensemble_filter_7 True
7.4 Ensemble output¶
libcdict can output its cdict variable in JSON format. This is human-readable, easy to parse in other languages (e.g. Perl, Python, C, C++, Java, Javascript, …).
When you output from binary_c
to the command line, output looks something like,but when output is to a buffer, e.g. for parsing by binary_c-python
, the whitespace is omitted.
"HRD" : {
"[C/Fe]" : {
"-5e-2" : {
"logTeff" : {
"3.65e0" : {
"logL" : {
"3.5e-1" : "7.271832039003311e1",
"4.5e-1" : "1.439654435074208e2",
"5.5e-1" : "1.1262333695232519e2",
...7.4.1 Deferred output¶
When you, or software such as binary_c-python
, run multiple stars, the default behaviour is to output a chunk of JSON after each star is run. Perhaps this is what you want, but perhaps instead you want to simply add the output of each star and only output when the final star is run. This reduces communications overheads, for example. To do this, set,
ensemble_defer TrueYou can test this with the tbse script, e.g.,
tbse repeat 10 random_systems True ensemble True ensemble_defer TrueThe ensemble JSON is output when the ensemble memory is freed, which only happens – if ensemble_defer is True – at the end of the run.
7.5 Adding to or changing the ensemble¶
While the ensemble outputs a lot of data, you will probably want something in the ensemble that’s not currently there. The ensemble is set in src/ensemble/ensemble_log.c and the other files in src/ensemble/ (which are called from
ensemble_log()) and you will need to change at least this file.7.5.1 Before you start¶
The Set_ensemble… macros look for two variables, p and dtp, as well as the ubiquitous stardata,
- p This is usually the probability.
- dtp This is usually the timestep multiplied by the probability.
So if you are doing ensemble logging, you should have two lines of code at the top of your function that usually look like this
const double p = stardata->model.probability; const double dtp = stardata->model.dt * p;
In ensemble_log(), you should use lineardt instead of stardata->model.dt, although this is already set up for you.
Some may ask, why not use the values in stardata directly? Well, you may want to do something else , and the above setup gives you the freedom to do so.
7.5.2 Adding to the ensemble cdict¶
The cdict itself is stored in stardata->model.ensemble_cdict which is of type struct cdict_t *. You can, of course, set and update the cdict variables using the libcdict API directly, but please do not do this. Instead, use the two macros Set_ensemble_count and Set_ensemble_rate.
- Set_ensemble_count allows you to count the number of types of stars. The weighting applied is where is the timestep and is the system’s probability.
- Set_ensemble_rate allows you to count the rate of events. The weighting applied is , the system’s probability. You should use Set_ensemble_rate for instantaneous events, such as mergers, supernovae and initial conditions (e.g. the initial mass function, which is instantaneous as it occurs only at exactly ).
The arguments to the above macros define a nested location in the ensemble hash. For example, the initial mass function is set with the following call.
Foreach_star(star)
{
if(born_binary == FALSE)
{
Set_ensemble_rate(
"distributions",
"initial log mass : label->dist",
"single",
"log mass",
(double)Bin_data(Safelog10(star->mass),0.1)
);
}
}The nested location is
"distributions" : "initial log mass : label->dist" : "single" : "log mass"which defines a cdict (“log mass”) in a cdict (“single”) in a cdict ("initial log mass : label->dist", this is called the label cdict, see Sec. 7.8) in a cdict (“distributions”) in the root cdict, which you cannot change (“ensemble_cdict”).The final variable in the list is the data, in this case the logarithm of the stellar mass, binned to the nearest
using Bin_data(). You should cast the result of Bin_data() to
(double) where necessary: libcdict has to otherwise guess the data type, which is notoriously difficult in C, and it may get it wrong (or set it differently using a different compiler or compiler version).In the above, we use Safelog10() to calculate the log of star->mass: this caps the value of star->mass to avoid
log(0).7.5.3 Binned data¶
Please, remember to bin your data. In the above call to set the initial mass function, the masses are binned to the nearest
. If you fail to bin data, remember the number of floating point values is large enough to fill your RAM many times over – at which point your code will crash (perhaps along with other software running on your machine).
You can use the
Bin_data(x,w) macro to bin data, where
is the data and
is the bin width. 7.5.4 Time¶
You should use the variable T in src/ensemble/ensemble_log.c as the time, e.g., T is not stardata->model.time, it is the appropriately binned output time, see 7.7.
const double CFe = nucsyn_elemental_square_bracket("C","Fe",
Xsurf,
stardata->common.Xsolar,
stardata);
const double CFe_binned = Bin_data(CFe,0.1);
Set_ensemble_count(
"distributions",
"(C)EMP period vs [C/Fe] : label->t->dist",
"all",
"time",(double)T,
"[C/Fe]",(double)CFe_binned);7.5.5 Fixed values¶
Sometimes you just want to set a value in the ensemble, rather than something modulated by the timestep or probability. You can do this with Set_ensemble_value, e.g.,You can also append to such a value, e.g. the following adds
to the above-set
,
Set_ensemble_value("useful information",
"my code version",(double)1.2345
); Set_ensemble_append("useful information",
"my code version",(double)1
); 7.5.6 Mean values¶
It is possible to log mean values also. This is something more of a challenge, because to calculate a mean the ensemble algorithm must sum a property, and then divide by a denominator. You can choose the denominator.
struct cdict_entry_t * const denominator =
Set_ensemble_denominator("IRAS",
"denominator"
);
Set_ensemble_mean(denominator,
"stellar data",
"star 0 mean mass",(double)stardata->star[0].mass
);Now, when is the normalization (division by denominator) done? It is done once when the JSON is output at the end of the run. Internally, when you set the denominator, the ensemble_apply_denominator() function is set in the cdict entry, then this is called by the JSON function, which proceeds to detect the callback in the cdict entry so the normalization cannot happen twice.
7.6 Processing the ensemble¶
The ensemble has a number of distinct sections, which may change depending on which output you decide to allow. Some examples are:
- scalars
- These are simple counts or rates expressed as a function of time. The labels for each are of the type ENSEMBLE_<name> which are defined in ensemble_1d.h. These are based on the legacy ensemble that was used for years from libcdict was introduced.
- number_counts
- These are number counts as a function of time that where not in the legacy ensemble, e.g. because they are multidimensional, such as a count of the numbers of stars of different stellar_types.
- distributions
- These are multidimensional distributions, either as a function of time or integrated through time (equivalent to assuming a constant star formation rate).
- HRD and HRD(t)
- These are special distributions, of or vs , they are Hertzsprung-Russell and/or colour-magnitude diagrams, and nested subdata. See ensemble_HRD.c.
7.7 Times of outputs¶
The variable T should be used in src/ensemble/ensemble_log.c to set the time of output. This is actually the binned time, which is set by the ensemble timestep. You can use either the time itself,
, or
. You can choose to use linear or log time.
- Linear time
- is set by default. The ensemble_dt binary_c
argument set the timestep in Myr.For example,
binary_c ... ensemble_dt 100 - Logarithmic time
- is turned on with ensemble_logtimes with a timestep set by ensemble_logdt. You will also have to set ensemble_startlogtime to define a time when logging stars, otherwise logging will start at
corresponding to
. For example,
binary_c ... ensemble_logtimes True ensemble_logdt 0.1 ensemble_startlogtime 0.1
Remember, the memory required to store data and the runtime increases as you shorten the timestep. Especially when running on cluster nodes, you will want to experiment with different timesteps to acquire the accuracy you require with the least use of resources.
7.8 Labels for automatic data processing¶
The ensemble examples above define labels (“metadata”) for each distribution which can be used for automatic data processing (see Sec. 7.11). For example, in the following,we have a label
Set_ensemble_count(
"distributions",
"log luminosity : label->dist",
"all resolved",
"log luminosity",(double)luminosity_binned
);"log luminosity : label->dist". This is a distribution of number of stars binned by log luminosity. The label is given metdata which describes the data format: label->dist, i.e. a label then a distribution. In this case, the label is “all resolved” and the distribution is "log luminosity",(double)luminosity_binned.The equivalent section of the ensemble JSON output is:
{
"distributions" : {
"log luminosity : label->dist" : {
"all resolved" : {
"log luminosity" : {
"-4.75e0" : "6.428191018390589e2",
"-4.65e0" : "1.573166303524993e3",
"-4.55e0" : "1.4997031226712315e3",
"-4.45e0" : "1.293876996317942e3",
"-4.35e0" : "1.0962803892305492e3",
"-4.25e0" : "9.204727786665062e2",
...
}
}
}
}
}7.8.1 Time dependence¶
You can include a time dependence with label->t->dist, e.g.,
Set_ensemble_count(
"distributions",
"log luminosity(t) : label->t->dist",
"all resolved",
"time",(double)T,
"log luminosity",(double)luminosity_binned
);7.8.2 Integer labels¶
You can define labels of the form Star 0 or Star 1, i.e. integer labels, as follows,
Set_ensemble_count(
"distributions",
"log luminosity : labelint->dist",
"star",(int)i,
"log luminosity",(double)luminosity_binned
);7.8.3 Maps¶
2D maps can be defined as follows. This sets up a map called merged log masses with abscissa (
-axis) primary and ordinate (
-axis) secondary:Because we want to output the masses of the stars just prior to them merging, we use the data from stardata->previous_timestep. The masses are binned to the nearest
and their logarithms are the values of the location in the map. We use Set_ensemble_rate() because mergers are treated as instantaneous events.
if(newly_merged)
{
Set_ensemble_rate(
"distributions",
"merged log masses : map",
"primary",
(double)Bin_data(
log10(Max(stardata->previous_stardata->star[0].mass,
stardata->previous_stardata->star[1].mass)), 0.1),
"secondary",
(double)Bin_data(
log10(Min(stardata->previous_stardata->star[0].mass,
stardata->previous_stardata->star[1].mass)), 0.1)
);
}You can nest a 2D map at any location you like.
7.9 The ensemble manager: making stellar population ensembles¶
You can use the Ensemble Manager, src/python/ensemble_manager.py, to launch and control stellar population ensembles in an automated way using inlists. Inlists are files which contain the input parameters to define one or more stellar populations.
Warning: the ensemble manager is considered experimental code. It works, but there are likely to be bugs, please use it and report them!
- The ensemble manager automatically handles running many stellar populations on your HPC cluster (with Slurm or Condor).
- The ensemble manager stores details of its various ensembles in an SQLite file ensembles.sql. This is very easy to probe using Python and allows very fast analysis of grids of models.
- Ensembles are each stored in their own directory identified with a UUID. You can find details of each ensemble in the db_chunk_JSON file should you not be able to probe ensembles.sql.
7.9.1 Ensemble manager commands¶
- To run anything to do with a grid of ensembles, run with the inlist as the first argument
ensemble_manager.py [comamnd] <inlist> - You can find some example inlists in $BINARY_C/src/inlists.
- You can do a dry run by setting the ENSEMBLE_MANAGER_DRY_RUN environment variable.
- Launch a grid with
ensemble_manager.py <inlist> launch - Stop running jobs with where you can choose columns to show (by default show them all)
ensemble_manager.py stop <inlist> stop (UUID|all) - Update the database
ensemble_manager.py stop <inlist> update - Obtain ensemble status with
ensemble_manager.py stop <inlist> status [columns] - Obtain ensemble long-format status with
ensemble_manager.py stop <inlist> longstatus - Show help
ensemble_manager.py help - Automatically make plotswhere if you also include the force argument all plots will be remade even if they already exist.
ensemble_manager.py makeplots [force]
7.9.2 Environment variables¶
- BINARY_C Points to the root binary_c directory. This must be set.
- ENSEMBLE_MANAGER_DIR The directory in which the database, and folders containing generated ensemble data, is to be stored. Defaults to: $HOME/data/populations-<binary_c_version>-<git_revision>-<project> where the binary_c_version is given by binary_c-config (e.g. 2.2.2), the git revision is like 5845:20220122:2b57e488e where the first number is the commit number, the second the date and the third is the commit MD5. The -<project> is set by self.runtime_vars[’miscellaneous’][’project’] and is ignored if this variable is set to None.
- ENSEMBLE_MANAGER_SCRIPT The script to be run to make ensemble data. Defaults to $BINARY_C/src/python/ensemble.py
- ENSEMBLE_MANAGER_PLOTSCRIPT The script to be run to plot an ensemble. Defaults to $BINARY_C/src/python/ensemble_plotter_threaded.py
- ENSEMBLE_MANAGER_DRY_RUN When set, launch commands do nothing but do report what they would have done, i.e. a dry run.
- ENSEMBLE_MANAGER_INLIST_PATHS By default, we look at the inlist’s full path, and also in $BINARY_C/src/inlist and $BINARY_C/src/python, for the inlist. You can specify a custom set of paths in $ENSEMBLE_MANAGER_INLIST_PATHS (separated by colons in the normal manner).
- ENSEMBLE_MANAGER_WRONG_REPO_WARNING If set, disable the warning that is given when the git repository revision does not match that of the currently-built binary_c.
7.10 ensemble.py: running individual stellar-population ensembles¶
Use the src/python/ensemble.py script to generate individual stellar-population ensembles using binary_c-python
. For example, runs a population with ensemble output every
starting at
, metallicity
on 24 threads using a
grid. The output is put in /tmp/ by default in ensemble_output.json.bz2. Note: the output is bzipped by default, you can unzip with
src/python/ensemble.py r=10 metallicity=0.0001 logdt=0.1 tstart=0.1 verbosity=1 num_cores=24bunzip2 <file>.There are many population options, such as initial distributions and stellar physics, which you can change in the script.
7.10.1 Ensemble JSON format¶
The ensemble_output.json file has contents like,which is the standard JSON output embedded in the
{
"ensemble" : {
"distributions" : {
"initial log luminosity : label->dist" : {
"all resolved" : {
"log luminosity" : {
"-0.05" : 0.0103126232202109,
"-0.15" : 0.0163602303936111,
"-0.25" : 0.0159375218663686,
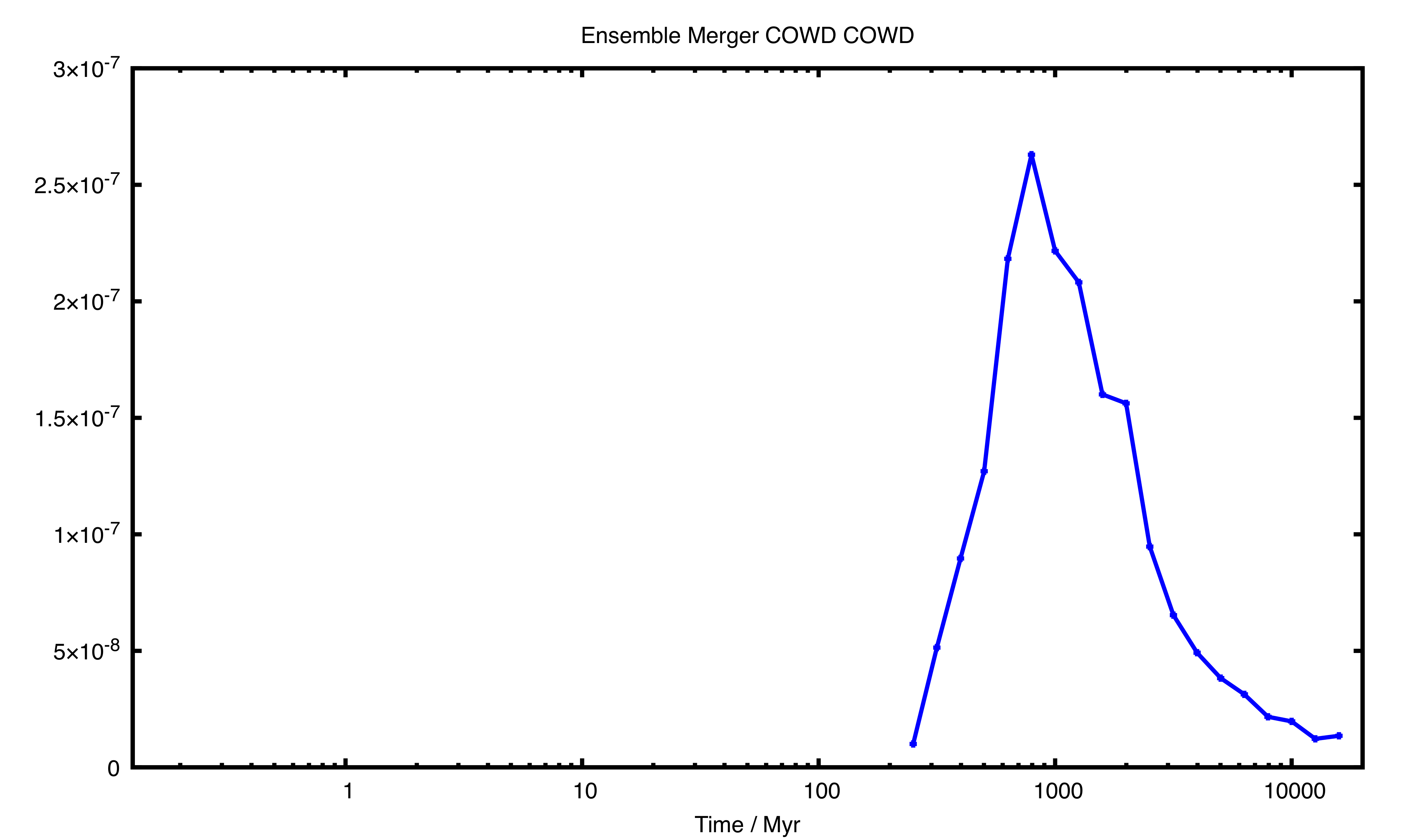
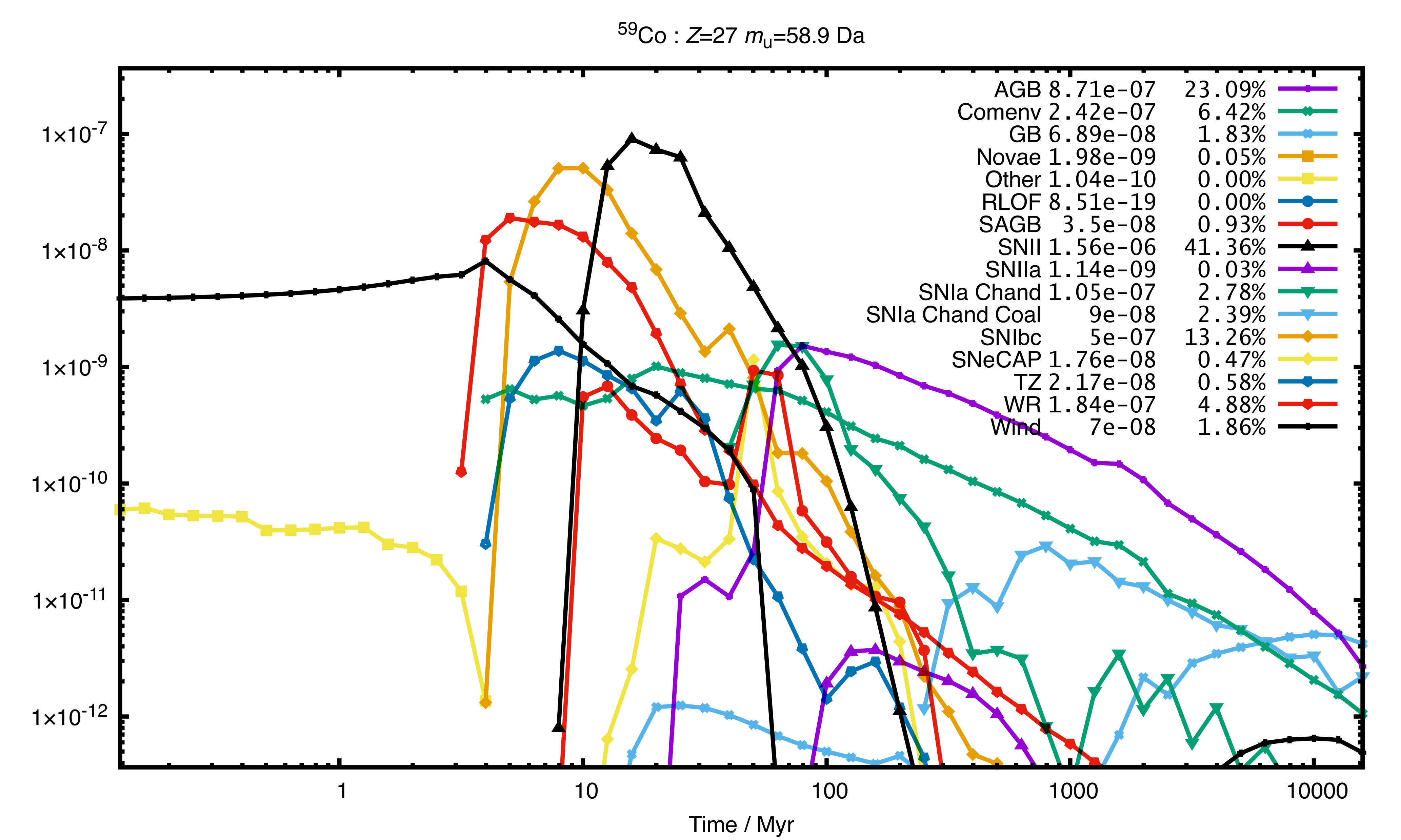
...“ensemble”. You can process this data yourself, e.g. with Perl use the JSON::Parse module, or with Python use the json module , or use the plot_ensemble.pl script as described in the following section to have everything done and plotted for you.7.11 Automatic data processing¶
You can use the binary_c
ensemble viewer, available at https://gitlab.com/binary_c/binary_c_ensemble_viewer, to make plots from ensemble data.

top8 binary_c API¶
The following describes functions in the binary_c C API. These functions are provided for access to binary_c through its shared library interface, libbinary_c.so, which is used by (for example) binary_c-python
. As of binary_c V2.3 you can access every function, i.e. all those usually internal to binary_c, through the extended API.
The main API functions very rarely change, even with new binary_c versions. The extended API, on the other hand, may well change from version to version. You should know this when using the extended API and be prepared to keep your code up to date.
8.1 Naming conventions¶
- Names of functions in the binary_c API start with binary_c_
- Names of functions in the binary_c extended API start with binary_cx_, so if you want to access a function xyz(…) in binary_c, your external code should refer call this as binary_cx_xyz(…).
- Functions in the API are declared with the attribute binary_c_API_function which makes sure they are always publicly available.
- Functions in the extended API are only publicly available if binary_c is built with the option -Dextended_API=true.
- The binary_c
structure types
- stardata_t
- star_t
- preferences_t
- store_t
- tmpstore_t
- model_t
- common_t
- etc.
should be declared in external code as- libbinary_c_stardata_t
- libbinary_c_star_t
- libbinary_c_preferences_t
- libbinary_c_store_t
- libbinary_c_tmpstore_t
- libbinary_c_model_t
- libbinary_c_common_t
- libbinary_c_…
This avoids name clashes with the functions of other libraries.
8.1.1 binary_c macros¶
Binary_c defines the following:
- RESTRICT
- This is set to __restrict__ or a suitable equivalent when available (this depends on the compiler).
- binary_c_API_function
- This is set to __attribute__ ((visibility("default"))) which is standard for exporting functions to shared libraries with gcc (and presumably clang). I have not yet investigated the equivalent for other compilers.
8.1.2 binary_c headers¶
Most binary_c
headers are loaded through binary_c.h. While it slows compilation to include all the headers, the convenience (and imposed structure) of having just one file to access headers overrides this.
8.2 Using the API¶
Using the API is simple in languages that can embed C directly, e.g. C, C++, Perl and Python. Some other languages, e.g. FORTRAN, require a special set of functions to be written in order to talk to them. Fortunately for you, I have already done this in FORTRAN.
Remember, if you are building an external program and want to include binary_c, you need to include libbinary_c.so when compiling. Usually this is with something like, assuming you are compiling with gcc,and you probably also need to include the libraries used by binary_c
which you can find withAt the time of writing, this gives mebut your build will differ, especially if you have not installed many of the optional libraries.
gcc ... -lbinary_c ...binary_c-config libs-lc -lgsl -lgslcblas -lm -lbacktrace -lbfd -lbsd -liberty -ljemalloc -lmemoize -lrinterpolate -lcdict8.2.1 In C¶
To include the API functions, binary_c.h must be included in your code.
8.2.2 Macro clashes¶
You may find there is a clash between binary_c
’s Max and Min macros (and perhaps others) and various standard libraries. In which case, use gcc’s push_macro/pop_macro feature to include your functions in the following way:
#pragma push_macro("Max")
#pragma push_macro("Min")
#undef Max
#undef Min
#include "binary_c.h"
/* ... your subroutines go here ... */
#undef Max
#undef Min
#pragma pop_macro("Min")
#pragma pop_macro("Max")
8.2.3 In C++¶
I have not written a wrapper in C++ because I figured you’d just use the C functions. However, it might make sense to wrap the C functions in some C++ objects and indeed given that the stardata struct functions very much like the data parts an object this should be quite trivial. Please let me know if you want to do this.
8.2.4 In FORTRAN¶
The file binary_c_API_fortran.c contains the API interface callable from FORTRAN. The example apitest.f90 (in the apitest directory) sets up and evolves a stellar system from FORTRAN. Please take note of the following points:
- Only the argstring interface works (no argc and argv)
- Remember to put a NUL character at the end of the argstring with char(0)
- There is a special function binary_c_fortran_api_stardata_info which can extract some data from a stardata struct. You must write code in C to extract the data, because FORTRAN knows little about C structures. This code is meant as an example: you can always write your own function and export it to your binary_c shared library with the binary_c_API_function macro.
The skeleton code below can be used as a basis to do whatever you like, see also aptitest.f90 in the apitest directory.
program binarycinfortran
use iso_c_binding
implicit none
character (len=1024) :: argstring
character (len=1024) :: format_string
type(c_ptr),pointer :: stardata_pointer,store_pointer
type(c_ptr),target :: stardata,store
stardata_pointer => stardata
store_pointer => store
stardata_pointer = C_NULL_PTR
store_pointer = C_NULL_PTR
format_string = '( "binary_c M_1 ",E10.3," M_2 ",E10.3," metallicity ",E10.3," orbital_period ",E10.3," eccentricity ",E10.3," max_evolution_time ",E10.3,A)'
write(argstring,format_string) 10.d0,5.d0,1d6,0.d0,0.02d0,15000d0,char(0)
call binary_c_fortran_api_new_system(stardata_pointer,C_NULL_PTR,C_NULL_PTR,store_pointer,argstring)
call binary_c_fortran_api_evolve_for_dt(dt,stardata_pointer)
call binary_c_fortran_api_free_memory(stardata_pointer,1,1,1)
end program8.2.5 In Perl¶
The Perl interface is deprecated.
8.2.6 In Python¶
Use binary_c-python
from https://gitlab.com/binary_c/binary_c-python.
8.3 Standard binary_c API functions¶
The following functions set up, evolve and modify stellar systems which are set up in stardata_t structures.
8.3.1 binary_c_new_system¶
void binary_c_API_function binary_c_new_system(
struct libbinary_c_stardata_t ** stardata,
struct libbinary_c_stardata_t ** previous_stardata,
struct libbinary_c_preferences_t ** preferences,
struct libbinary_c_store_t ** store,
char ** argv,
int argc);
- stardata must be a pointer to a libbinary_c_stardata_t struct pointer. The memory for the stardata is allocated by this function.
- previous_stardata is usually NULL, in which case space for it is allocated. If non-NULL, it must point to a previously allocated libbinary_c_previous_stardata_t struct.
- preferences is allocated and set up if NULL, or should be a pointer to a pointer to a previous allocated libbinary_c_preferences_t struct.
- store must be a pointer to a libbinary_c_store_t struct pointer which is empty and NULL, or a pointer to a pointer to a previously allocated libbinary_c_store_t struct. This feature enables you to make the store only once, but call binary_c_new_system repeatedly with it, thus saving a lot of CPU time.
- store is a pointer to a libbinary_c_persistent_data_t struct pointer which, if NULL, is allocated. This enables you to store data between binary_c runs.
- argv and argc are, if argc is not -1, a set of arguments identical in format to the standard C command line arguments.
Alternatively, set argc to -1 then argv can be a pointer to a string containing a set of arguments (which must start with the word “binary_c” as this would be the first argument in the standard C format). These are split in binary_c and parsed as usual.
For example, the following makes a new stellar system in stardata and sets up new store and persistent data structures.
struct libbinary_c_stardata_t * stardata = NULL;
struct libbinary_c_store_t * store = NULL;
struct libbinary_c_persistent_data_t * persistent_data = NULL;
char * argstring = "binary_c M_1 10 M_2 5 orbital_period 100 eccentricity 0.0 metallicity 0.02";
binary_c_new_system(&stardata,
NULL,
NULL,
&store,
&argstring,
&persistent_data,
-1);
/* ... */8.3.2 binary_c_evolve_for_dt¶
This function evolves a stellar system defined in a stardata struct for a time dt Myr.
int binary_c_API_function binary_c_evolve_for_dt(struct libbinary_c_stardata_t * const stardata,
const double dt);- stardata is defined previously (Sec. 8.3.1)
- dt is the number of MYr (megayears, )
Typically, output is sent to stdout, but you can capture it in a buffer. Please see Sec. 8.5.2.
8.3.3 binary_c_buffer_info¶
This function returns a pointer to the binary_c
output buffer and its size.
void binary_c_API_function binary_c_buffer_info(struct libbinary_c_stardata_t * RESTRICT const stardata,
char ** const buffer,
int * size);- stardata is defined previously (Sec. 8.3.1)
- buffer is a pointer to a char* which points to binary_c ’s internal buffer. Any changes you make to the contents of buffer thus also change binary_c ’s internal buffer.
8.3.4 binary_c_error_buffer¶
This function returns a pointer to the binary_c
error buffer.
void binary_c_API_function binary_c_error_buffer(struct stardata_t * RESTRICT const stardata, char ** const error_buffer)- stardata is defined previously (Sec. 8.3.1)
- error_buffer is a pointer to a char** which points to a pointer to binary_c ’s internal error buffer.
- Unlike the normal buffer defined above, this buffer is of fixed size so you don’t have to worry about its length.
8.3.5 binary_c_buffer_empty_buffer¶
This function frees the memory used in binary_c
’s internal buffer. See also Sec. 8.3.3.
void binary_c_API_function binary_c_buffer_empty_buffer(struct stardata_t * RESTRICT const stardata); - stardata is defined previously (Sec. 8.3.1)
8.3.6 binary_c_free_store_contents¶
Once you have finished running (possibly many) stellar systems, you can free the contents of the store struct with a call to binary_c_free_store_contents
void binary_c_API_function binary_c_free_store_contents(struct libbinary_c_store_t * RESTRICT const store);- store is defined previously (Sec. 8.3.1)
8.3.7 binary_c_free_memory¶
Once your stellar evolution has finished, a stardata struct needs to have its memory freed. This function enables you to free the stardata, preferences, store structs and the raw_buffer if required. It is possible that preferences and store should not be freed, because these can be reused for future evolutionary runs.
void binary_c_API_function binary_c_free_memory(struct stardata_t ** RESTRICT const stardata,
const Boolean free_preferences,
const Boolean free_stardata,
const Boolean free_store,
const Boolean free_raw_buffer,
const Boolean free_persistent);- stardata is defined previously (Sec. 8.3.1)
- free_preferences, free_stardata, free_store, free_raw_buffer and free_persistent should be either TRUE or FALSE.
8.3.8 binary_c_free_store_contents¶
This is like binary_c_free_memory but only frees the store struct stored in stardata.
void binary_c_API_function binary_c_free_store_contents(
struct stardata_t * RESTRICT const stardata
)8.3.9 binary_c_free_persistent_data¶
This is like binary_c_free_memory but only frees the persistent_data struct stored in stardata.
void binary_c_API_function binary_c_free_persistent_data(
struct stardata_t * RESTRICT const stardata
)8.4 Extension functions¶
A few functions have been defined which provide extensions to the basic API and are very useful in binary_c-python
module. The number of extension functions may increase in the future, so this documentation is always likely to be out of date.
8.4.1 binary_c_version¶
This function provides access to the (long) version string returned by binary_c
void binary_c_API_function binary_c_version(struct libbinary_c_stardata_t * RESTRICT const stardata);- stardata is defined previously (Sec. 8.3.1)
8.4.2 binary_c_list_args¶
This function provides a list of the arguments which could be used to run a stellar system. This is useful when constructing wrappers around binary_c
, such as binary_c-python
.
void binary_c_API_function binary_c_list_args(
struct libbinary_c_stardata_t * RESTRICT const stardata)- stardata is defined previously (Sec. 8.3.1)
8.4.3 binary_c_show_instant_RLOF¶
This function provides access to the binary_c function that determines the minimum orbital period or separation that leads to instantaneous Roche-lobe overflow for a given
,
and metallicity.
void binary_c_API_function binary_c_show_instant_RLOF(struct libbinary_c_stardata_t * const stardata);- stardata is defined previously (Sec. 8.3.1)
- Note that binary_c_show_instant_RLOF_period_or_separation is identical to this function (it is kept for old code).
8.4.4 binary_c_initialize_parameters¶
This function calls the binary_c
initialize_parameters function which in turn is useful for reporting the initial abundance mixture.
void binary_c_API_function binary_c_initialize_parameters(struct libbinary_c_stardata_t * RESTRICT const stardata);- stardata is defined previously (Sec. 8.3.1)
8.4.5 binary_c_help¶
This function outputs the help associated with argstring using Printf (i.e. to the screen or into binary_c
’s raw_buffer depending on how you have set stardata->preferences->internal_buffering).
void binary_c_API_function binary_c_help(struct stardata_t * RESTRICT const stardata,
char * argstring)- stardata is defined previously (Sec. 8.3.1).
- argstring is a string provided by the user.
8.4.6 binary_c_events_replace_handler_functions¶
This function allows you to replace the default event handler functions with your own.
binary_c_API_function
void binary_c_events_replace_handler_functions(
struct stardata_t * const stardata,
const Event_type type,
Event_handler_function func(EVENT_HANDLER_ARGS))- stardata is defined previously (Sec. 8.3.1)
- The event is defined by its type and its handler func. For example, the supernova event handler function looks like this.Please check Sec. 9.12 for more details.
Event_handler_function supernova_event_handler(void * const eventp MAYBE_UNUSED, struct stardata_t * const stardata, void * data MAYBE_UNUSED) { //struct binary_c_event_t * event = eventp; // you may want this ... /* do stuff */ return NULL; }
8.4.7 binary_c_generic_event_handler¶
When you override an event handler, you may still want to call the event handler that binary_c
would normally use as well as your own function. Call binary_c_generic_event_handler to do this.
- eventp is a pointer to the event struct: see Sec. 8.4.6 to retrieve this.
- stardata is defined previously (Sec. 8.3.1)
- data is data passed to the generic handler function.
binary_c_Event_handler_function
binary_c_API_function
binary_c_generic_event_handler(
void * const eventp MAYBE_UNUSED,
struct stardata_t * const stardata,
void * data MAYBE_UNUSED)8.4.8 binary_c_catch_events¶
This is equivalent to calling catch_events() so you can trigger events stored in stardata’s events stack.
binary_c_API_function void binary_c_catch_events(struct stardata_t * stardata)
8.4.9 binary_c_erase_events¶
This is equivalent to calling erase_events() so you can erase events stored in stardata’s events stack.
binary_c_API_function void binary_c_catch_events(struct stardata_t * stardata)
8.4.10 binary_c_copy_stardata¶
This function allows you to copy a stardata struct.
- The arguments from and to are pointers to allocated stardata structs. from and to should never be identical, otherwise binary_c will raise a BINARY_C_POINTER_FAILURE error.
- copy_previous can be one of the following
- COPY_STARDATA_PREVIOUS_NONE : do nothing, the new previous_stardatas stack is left NULL
- COPY_STARDATA_PREVIOUS_COPY : make a copy of history data into a new previous_stardatas stack
- COPY_STARDATA_MAINTAIN_FROM_STACK_POINTERS : use from’s previous_stardatas stack pointers
- COPY_STARDATA_MAINTAIN_TO_STACK_POINTERS : use to’s previous_stardatas stack pointers
- copy_persistent can be one of the following
- COPY_STARDATA_PERSISTENT_NONE : do nothing, leave persistent data NULL
- COPY_STARDATA_PERSISTENT_FROM_POINTER : copy from’s pointer, i.e. use the existing persistent_data
- COPY_STARDATA_PERSISTENT_COPY_SHALLOW : make a shallow copy of the persistent_data struct, maintaining any pointers within it as they were
- COPY_STARDATA_PERSISTENT_COPY_DEEP : make a deep copy of the persistent_data struct (calls copy_persistent() which contains custom code for each item in the persistent_data struct)
binary_c_API_function
struct stardata_t * Returns_nonnull Nonnull_all_arguments
binary_c_copy_stardata(
const struct stardata_t * RESTRICT Aligned const from,
struct stardata_t * RESTRICT Aligned const to,
const unsigned int copy_previous,
const unsigned int copy_persistent
)8.4.11 binary_c_check_reject_flags¶
This function allows you to check the timestep rejection flags in stardata (see check_reject_flags()).
int binary_c_API_function binary_c_check_reject_flags(
struct stardata_t * RESTRICT const stardata)- stardata is defined previously (Sec. 8.3.1)
8.5 API Examples¶
There are several examples of using the API.
8.5.1 Arguments and/or the argstring¶
The argstring, or a combination of argc and argv, is used to send commands to binary_c
, and this is sent to binary_c_new_system() to specify (say) masses, orbits, metallicity etc. prior to a call to evolve a stellar system. You do not have to send an argstring, you could set the system directly, e.g.
stardata->star[1].mass = 10.0;
stardata->common.metallicity = 0.02;
stardata->model.max_evolution_time = 15000.0;but there are some functions which are called after the arguments are parsed which would be skipped if you do it manually. You will have to mimic (or copy from binary_c
) this functionality.
8.5.2 Capturing the buffer output¶
Usually, output is sent to the stdout stream. However, it is often more useful to capture the output and process it in an automated way. You can do this with the following code which sets up a stellar system, suppresses logging to files, sets up the internal buffer, evolves the system, then grabs the buffer into memory. It is up to you to process this buffer but it must then be freed before you finish.
struct libbinary_c_stardata_t * stardata = NULL;
struct libbinary_c_store_t * store = NULL;
struct libbinary_c_persistent_data_t * persistent_data = NULL;
char * argstring = "binary_c M_1 10 M_2 5 orbital_period 100 eccentricity 0.0 metallicity 0.02";
binary_c_new_system(&stardata,
NULL,
NULL,
&store,
&persistent_data,
&argstring,
-1);
/* suppress logging and use internal buffer */
strcpy(stardata->preferences->log_filename,"/dev/null");
strcpy(stardata->preferences->api_log_filename_prefix,"/dev/null");
stardata->preferences->internal_buffering = INTERNAL_BUFFERING_STORE;
stardata->preferences->batchmode = BATCHMODE_LIBRARY;
binary_c_evolve_for_dt(stardata,stardata->model.max_evolution_time);
char * buffer = NULL;
char * error_buffer = NULL;
int nbytes = 0;
/*
* Get the binary_c output in *buffer and the
* error buffer in *error_buffer
*/
binary_c_buffer_info(stardata,&buffer,&nbytes);
binary_c_error_buffer(stardata,&error_buffer);
/* check the error buffer */
if(error_buffer != NULL)
{
fprintf(stderr,"Error in binary_c : %s\n",error_buffer);
}
else
{
/* process the buffer */
/* ...... your code goes here ...... */
}
/* free used memory */
binary_c_free_memory(&stardata,TRUE,TRUE,TRUE,TRUE,TRUE);8.5.3 Memory management and maintaining a store¶
Memory is allocated during a call to binary_c_new_system() which sets up the stardata struct, the preferences struct and the store struct. Both the preferences and the store can be reused once defined, which means you do not have to go through the costly (in CPU cycles) process of setting up a multitude of data for each stellar system. The example below runs a number of systems while preserving the store. It is not recommended to preserve the preferences even though it is possible.
struct libbinary_c_stardata_t * stardata = NULL;
struct libbinary_c_store_t * store = NULL;
struct libbinary_c_persistent_data_t * persistent_data = NULL;
unsigned int n = 0; // loop until n = 10
while(n++ < 10)
{
char * argstring;
/*... code to define your args ...*/
binary_c_new_system(&stardata,
NULL,
NULL,
&store,
&persistent_data,
&argstring,
-1);
binary_c_evolve_for_dt(stardata,stardata->model.max_evolution_time);
/* process (buffered) data here or maybe do nothing with it */
/* ... */
/* free everything except the store */
binary_c_free_memory(&stardata,TRUE,TRUE,FALSE,TRUE,TRUE);
}
/* free the store memory */
binary_c_free_store_contents(store);
store = NULL;
/* ... do your data processing ... */You can also free everything with the following function call:
binary_c_free_memory(&stardata,TRUE,TRUE,TRUE,TRUE,TRUE); binary_c_free_memory(&stardata,TRUE,TRUE,TRUE,TRUE,TRUE);
store = NULL;
stardata = NULL; You must not call binary_c_free_memory to free your stardata and store and then immediately use Safe_free on these pointers. They have already been freed, just not set to NULL (because it is impossible to do so in binary_c_free_memory), and freeing them – even with Safe_free – will cause a crash. Instead, just set them to NULL.
If you are concerned that memory has not been freed, try running binary_c
through valgrind or enable the CODESTATS flag in binary_c_code_options.h. If you cannot find the problem, or if it’s a problem not of your making, please contact Rob about it so that it can be fixed for everyone.
8.6 Building binary_c with the extended API¶
You can check if the extended API is on by checking for that the BINARY_C_EXTENDED_API macro is set.
$ ./binary_c version | grep "BINARY_C_EXTENDED_API is"
BINARY_C_EXTENDED_API is on$ ./binary_c-config full_version |grep "BINARY_C_EXTENDED_API is"
BINARY_C_EXTENDED_API is on $ ./binary_c-config cflags |grep -o BINARY_C_EXTENDED_API
BINARY_C_EXTENDED_APItop9 Code description and internals¶
This section describes some of the internal details of the binary_c
code.
9.1 History¶
First, a bit of history. The BSE code was given to me by Chris Tout in October 2000 and some updates were made in May 2001 (from Jarrod Hurley). Jarrod was responsible for the October 2000 version, written as one monolithic block of evil Fortran, although past collaborators such as Chris Tout, Sverre Aarseth, Onno Pols etc. (who else have I forgotten?) had input their talent to the code. The Fortran version was converted to C (because I hate Fortran and it was my bloody PhD!) and (some of) the bugs worked out of it. This gave me a chance to lay the code out quite differently.
One major change is in the organisation of the variables. In the Fortran code there are many arrays of size 2, there are two stars, and a load of evil common blocks. These have been replaced by two structures, one for each star, the common and model structures, a preferences structure to contain user-defined options, and a stardata structure which contains pointers to everything else. Pointers are far quicker to use than passing the actual data around. Conceptually it’s useful to have all the information about the system, in stardata, easily accessible to all functions through a single pointer.
Throughout the code you’ll see lots of Dprint statements, these are enabled when debugging is turned on. These are very useful when something goes wrong (see section 9.5.3).
If you change anything, and would like me to debug it or you would like to commit it to the
branch, I insist on the following.
- Learn about how to write C, e.g. https://www.maultech.com/chrislott/resources/cstyle/indhill-cstyle.pdf or https://en.wikipedia.org/wiki/The_C_Programming_Language.
- Learn how to format your C code properly. Section 9.14 describes the required layout.
- Include good comments even if these are “this is a fudge”. Remember that people who do not know how the code works will want to change the code in the future, and I have to check it before it is committed. Descriptions of the physics, paraphrased from a paper if you have to (but remember to give appropriate credit), are encouraged. Lists of input and output variables are required for new functions.
- Include Dprint() statements so that if there is a DEBUG flag set there will be some (useful!) output to the screen during runtime.
- Make sure the names of your variables describe what they do in English. I do not care if the variable names are long (long is good!) and the computer certainly doesn’t either.
9.2 How the binary_c code works¶
The binary_c
code, based on BSE, deals with stellar evolution and binary evolution i.e. the mass, core mass, luminosity, radius of both stars, mass loss and gain, orbital changes, supernovae and novae. Its nucleosynthesis (“nucsyn”) code deals with the surface abundance of the stars, follows this as mass is lost or gained and also the luminosity and radius on the TPAGB, dredge-ups, HBB, WR stars, supernova and nova yields. This does not sound like much but it’s complicated enough! So as the binary_c
code does the stellar (“structure”) evolution, the nucsyn code identifies when the surface abundances change.
9.3 Memory management in binary_c ¶
9.3.1 Memory allocation¶
Memory should be allocated using the macros Malloc, Calloc and Realloc which replace the system malloc, calloc and realloc, respectively. These macros allow for automatic error checking, e.g. when an allocation fails (i.e. when ALLOC_CHECKS is defined), as well as the use of aligned memory (which should be faster).
9.3.2 Stack size¶
The allocation of big data tables can require a large stack. Please remember to set your stack size, either in your shell e.g. with ulimit appropriately. If your stack is too small, you will find (possibly random) segmentation faults. See section 9.5.5 for more information.
9.3.3 Main Memory Structures: stardata¶
Memory use in binary_c
is divided into structures which are allocated appropriately. The main structure, a pointer to which is passed around all over the place, is stardata. Normally this is all you need. However, there are structures for specific purposes as described below. Memory allocation is mostly done in the main_allocations subroutine.
Variables are stored as arrays within, e.g., stardata, which is dynamically allocated on the heap, rather than being dynamically allocated themeslves. You should probably not use stardata as a local stack variable, because it is liable to be quite large.
- stardata_t
- The main stardata structure is used to store the information about the stellar system currently being evolved, as well as pointers to all the other memory stores. stardata is set to 0 (the NULL byte ’\0’) at the beginning of evolution, so everything inside it is either zero (for floats, doubles, ints etc.), or FALSE (for Booleans).
- previous_stardata_t
- A pointer to the top of the previous_stardata stack. This is used at the end of an evolutionary step to calculate derivatives and perform logging (e.g. change of stellar type).
- previous_stardatas
- A stack of copies of stardata->n_previous_stardatas previous timesteps’ stardata structures.
- stardata_stack
- A stack of stardata->n_stardata_stack temporary stardata structures used by the various numerical integration schemes (e.g. RK2, RK4). These are generally not final solutions – they are intemediate – and hence should never be touched.
- common_t
- The common structure stores data that is persistent for this particular stellar system and relates to properties of the system. The space for this structure is inside stardata. This structure should not contain dynamically allocated memory. common is inside stardata so is set to 0 (the NULL byte ’\0’) at the beginning of evolution, so everything inside it is either zero (for floats, doubles, ints etc.), or FALSE (for Booleans).
- model_t
- The model structure stores data that is persistent for this particular stellar system and relates to the details of the binary model at a given time. The space for this structure is inside stardata. This structure should not contain dynamically allocated memory. model is inside stardata so is set to 0 (the NULL byte ’\0’) at the beginning of evolution, so everything inside it is either zero (for floats, doubles, ints etc.), or FALSE (for Booleans).
- star_t[NUMBER_OF_STARS]
- The information stored to describe each star. NUMBER_OF_STARS of these are in an array inside stardata. This structure should not contain dynamically allocated memory. star[] is inside stardata so is set to 0 (the NULL byte ’\0’) at the beginning of evolution, so everything inside it is either zero (for floats, doubles, ints etc.), or FALSE (for Booleans).
- preferences_t
- The preferences structure contains information about how a system should be set up and what physics apply. The location of preferences is saved as a pointer in stardata but its data are not stored in stardata, thus this structure must be allocated and set up separately. This structure should not contain dynamically allocated memory.
- store_t
- The store structure contains data which is constant, e.g. data tables. Space for the store is allocated on the first run, and it can be kept at the end of the run, so the store only has to be set once (or once per thread). The data in store should be dynamically allocated (e.g. with MALLOC, CALLOC, REALLOC). The store is built in the build_store_contents function, and deleted in the free_store_contents function.
- tmpstore_t
- The tmpstore contains data which is required to be shared between functions, but is not required to be shared after the current evolutionary timestep is complete. Such data should be dynamically allocated, and each function which uses the tmpstore should check if the appropriate pointer is NULL in which case it should allocated the memory. The free_tmpstore function deletes the data when required. This is usually at the end of stellar evolution, but potentially sooner if many stardata structures are being switched in and out with the API. Data which is required to be persistent between timesteps, which is not constant, and which survives a change in stardata, should be in common. Constant data should be in store.
- data_table_t
- This stores information describing an interpolation table, including the number of parameters, number of values to be calculated, length of the table and the table data. See the rinterpolate function from librinterpolate.
- new_supernova_t
- This is a structure that stores information used by the supernova functions.
- splitinfo_t
- This contains information used by the evolution splitting algorithm.
- diffstats_t
- This structure is used to compare the state of the stellar system to that of the previous timestep. Changes are then logged.
- probability_distribution_t
- A generic probability distribution description.
- power_law_t
- Defines a power law, used in the discs code.
- disc_thermal_zone_t
- Defines a thermal zone in a disc, used in the discs code.
- disc_loss_t
- Defines a mass/angular-momentum loss/gain rate, used in the discs code.
- disc_t
- Defines a disc, used in the discs code.
- new_stellar_structure_t
- Defines, in a (hopefully) code-independent way, the stellar structure. Used to interface the generic stellar structure algorithm with binary_c .
- RLOF_orbit_t
- Information on mass loss/transfer/gain during RLOF.
- binary_system_t
- Defines the binary system for use with the discs code.
- kick_system_t
- Information used by the (supernova) kick code.
- mersenne_twister_data
- Used by the random number generator.
- binary_c_file
- Used by the file access routines, e.g. to store the amount of data written to a file and hence prevent it getting too large.
- binary_c_fixed_timestep
- Used to make “fixed” timesteps, e.g. so you can output every n million years, exactly (also works in log time).
- binary_c_event_t
- Used in the events code (see Section 9.12). There are various other custom structures which store data for events (see binary_c_structures.h)
9.3.4 Supplementary data structures¶
There are a number of other data structures used by binary_c. A few are listed here and most are not of interest to you.
- data_table_t
- This contains information about a data table. Set up (a pointer to, i.e. data_table_t*) the data table through NewDataTable_from_Array or NewDataTable_from_Pointer. Access the data table through the Interpolate macro (which interfaces with librinterpolate). Delete the table with Delete_data_table. The data_table_t.data pointer points to an array of doubles which contains the data: this memory is not allocated for you. If set up in the store or tmpstore this can be dynamically allocated, elsewhere you have to be careful and probably point to a data array inside stardata.
If you want to set up a data_table_t rather than a data_table_t* you will have to do it manually. - splitinfo_t
- This contains information used when EVOLUTION_SPLITTING is defined. See evolution_split.
- diffstats_t
- Used in constructing the standard log file. See evolution_difflog.
- probability_distribution_t
- Not sure this is used at present: it defines a probability distribution.
- power_law_t
- Used to define a power law used by the disc code.
- disc_thermal_zone_t
- Used to define a thermal zone of a disc in the disc code.
- disc_t
- Used to define a disc in the disc code.
- binary_system_t
- Used to define the properties of a binary-star system in the disc code.
9.3.5 Thread safety¶
binary_c
, as of version 2.0pre21 and in all subsequent versions, i.e. in the version you are using!, is designed to be thread-safe, i.e. it can be built as a shared library (
make libbinary_c.so) and deployed in many threads by one process (as in binary_c-python
). To this end:- You may not use static variables. Put your data into stardata.
- You may not use global variables (i.e. no extern statements). Put your data into stardata.
- You may not use non-thread-safe C library functions (e.g. strtok and hash functions, use the _r or _s equivalents). Some of these functions have been redefined as macros in binary_c – these macros will deliberately fail the compilation process and hopefully give you a warning.
- You must follow the conventions given above regarding memory allocation in stardata.
Please use the memory structures appropriately (see 9.3.3).
9.4 Output¶
binary_c
must communicate its results to you somehow otherwise what is the point? When running one star, it is sufficient to send output to either the screen (stdout) or to a file (with redirection, e.g. tbse > file). When running millions of stars, output must be sent to, e.g., a function you define when using binary_c-python
. In this case, either data is sent through a pipe or in an array in memory. Thus, binary_c
has to intercept your output and decide where to send it. This is done as follows.
- Use Printf instead of printf: Printf sends data to buffered_printf. This stores raw output data in a buffer, and outputs either immediately, at the end of evolution, or not at all, depending on what you want to do with the buffer. It is up to you to clear out the buffer after evolution (or on a switch of stardata) with a call to buffer_empty_buffer. You can get the pointer used to store the buffer from buffer_info.
- binary_c defines a macro printf in binary_c_code_options.h which overrides the default printf and means you can change default printf behaviour.
- Use _printf to force output to stdout using the C-library’s fprintf function.
- Ensemble output is, if deferred (Sec. 7.4.1), only output once at the end of the grid run. This should be fast, whatever you do, because this only happens once. This can be a lot of data though.
- warning: experimental If BUFFERED_STACK is defined, you can use binary_c_stack_printf, which is a more advanced buffer with a full stack API (e.g. push and pop functions), that can include (zlib) compression. However, at present this is not used, and may never be a standard part of binary_c .
9.5 Debugging binary_c ¶
I give here some general strategies for debugging binary_c
, but of course there are many ways to debug code. To summarise, you have these options:
- Check the log file, e.g. to see what is wrong, and fix it.
binary_c log_filename <whatever> - Put in your own
printf-style statements. Remember tofflush(stdout);if you are experiencing segmentation faults to make sure the operating system’s buffer is flushed (alternatively, usestdbuf -o0 binary_c ...to disable buffering). - Use binary_c ’s DEBUG facility to output useful information. See section 9.5.3.
- Use a debugging tool like gdb or valgrind.
9.5.1 General strategy¶
The usual problem is that you are running a grid of stars and one star causes binary_c
to crash. If you are lucky, this does not bring down the whole grid, but it might (especially if you are using the C backend). It is important to identify precisely which star caused the crash. You will find this very hard to do if you are running a grid with more than one thread, because any thread could have caused the crash. So, the first thing you must do is run your grid with only one thread, and with binary_c-python
verbosity set to at least 2 (e.g. run <script> verbosity=3). This will tell you the arguments which were sent to binary_c
that caused the crash. Save these to a file.
Next, you should run binary_c
with exactly these arguments. This is very easy, just run
./binary_c <arguments>You should see output, and (hopefully) the same failure as caused the grid to crash. Now you can debug binary_c
properly, in an isolated test case.
Note that the idea of isolating a test case which causes a failure is good practice in science and engineering in general, so you’re doing nothing unusual here. The strategy now is:
- If you are seeing a segmentation fault, you probably want to now debug with valgrind or gdb.
- If your problem is in your algorithm and is not really a coding error as such, you probably want to use the internal debugging with DEBUG, DEBUG_EXP and Dprint. See Section 9.5.3 below.
9.5.2 Debug builds¶
When debugging, it is important to disable any optimisation the compiler uses and turn on options that allow the code to be debugged with gdb and/or valgrind, and use the backtrace feature (see Section 9.5.4). This is called a “debug build”. You can reconfigure your builddir with
cd builddir
meson setup --reconfigure --buildtype=debug
ninja binary_c_install
cd ..9.5.3 DEBUG, Dprint and friends¶
Internal debugging in binary_c
is very useful to determine where an algorithm fails. It is not so useful in determining where segmentation faults and memory errors occur, although it is obviously useful in the sense that debugging will continue until a crash. Binary_c
provides the macro to allow you to output what is going on to the screen (usually to stdout). To turn this on, in binary_c_debug.h file the line similar to the following and change it to:Then rebuild with debugging enabled,
Dprint(...)#define DEBUG 1cd builddir
meson setup --reconfigure --buildtype=debug
ninja binary_c_installThere are other options in binary_c_debug.h:
- You can provide an expression which must return true for debugging statements to be output. This is Debug_expression in binary_c_debug.h. E.g. to only have output after 10Myr, use:Again, you will need to do a complete rebuild to make this work.
#define Debug_expression (stardata->model.time > 10.0)
By default, Debug_expression is set to 1 so there is output always. This may be a lot of data! - You can use Dprint_no_newline() macro to prevent the newline after a debugging statement.
- If you want to stop your star at some point, use Debug_stop_expression, e.g. to stop when the mass star 0 is less than
:
#define Debug_stop_expression (stardata->star[0].mass < 10.0) - Debugging output lines start with Debug_show_expression, e.g. to output the model number and stellar masses at each timestep,
#define Debug_show_expression " model %d st: %g %g ", \ stardata->model.model_number, \ stardata->star[0].mass, \ stardata->star[1].mass - You can change the output stream, usually one of stdout or stderr, by changing the macro DEBUG_STREAM.
- You can output file line numbers and filename output with DEBUG_LINENUMBERS and DEBUG_SHOW_FILENAMES.
- If there is an inf or nan in the output, you can force binary_c to stop by defining DEBUG_FAIL_ON_NAN or DEBUG_FAIL_ON_INF. You should define DEBUG_REMOVE_NAN_FROM_FILENAMES so that filenames have “nan” converted to “n_n”, otherwise “remnant” will trigger an exit.
When you now run tbse you will see many lines of data. These correspond to Dprint lines in the binary_c code.
You can change the output of Dprint in src/debug/debug_fprintf.c
Another macro, Dprint_no_newline, is the same as Dprint but without a “\n” newline at the end of the string.
9.5.4 Backtrace¶
If BACKTRACE is defined (in binary_c_code_options.h) you have access to stack tracing features similar to those used in debuggers. Please install libbacktrace before expecting this to work. Calling the Backtrace macro (with no arguments) allows you to see a list of callers of any function, anywhere in binary_c
, through the print_trace function. This is a very useful feature if you want to see which function called the function in which you have a problem. Note that it is, however, quite slow, and requires a debug build.
Note that this feature has not been tested on platforms other than Linux.
meson setup -Dvalgrind=true builddir9.5.5 Segmentation faults¶
As with any code with large chunks of data being dynamically allocated, any attempt to access data which is not allocated leads to a segmentation fault. It is often extremely difficult to determine where the cause lies, as it may be somewhere previous in the program, or even on another thread. Should you encounter such a segmentation fault, please try running through gdb and/or valgrind to locate the cause.
9.5.6 gdb¶
The Gnu debugger, gdb, is a useful option for quickly finding the location of a segmentation fault. Run
tbse debugbt9.5.7 valgrind and friends¶
Valgrind is a step up in technology from gdb. It not only locates segmentation faults, it also determines when (heap) memory is overwritten when it should not be, or unallocated memory is accessed. These are the two main causes of segmentation faults, so valgrind really is your friend.
- Note: you may find that some CPU instructions must be disabled because they are not (yet) supported by Valgrind. Examples include the avx512 instructions. You can configure the binary_c
build for Valgrind with
meson setup -Dvalgrind=true builddir
There are many tools associated with valgrind:
- memcheck: this is the standard valgrind tool for finding problems with (heap) memory access issues that lead to segmentation faults. Because the memory allocated in binary_c
is mostly on the the heap (e.g. stardata is allocated with MALLOC) it is the most useful of valgrind’s tools.
Run this withNote that the valgrind options in tbse work for me, but you may need something a bit different, in particular you may need to change the stack size and maximum stack frame.tbse valgrind - massif
I cannot remember what this does! Run this with
tbse massif - callgrind: a tool to profile code i.e. determine where time is spent and hence optimize.
Run this with
tbse callgrind - cachegrind: a tool to analyse cache hits. Run this with
tbse cachegrind - sgcheck: a tool for stack array overrun analyisis.
Run this with
tbse sgcheck - drd : a tool for thread analysis
Run this with
tbse drd
You can override the arguments sent to valgrind by tbse by setting the environment variable VALGRIND_ARGS.
9.5.8 Thread safety¶
binary_c
and its shared library libbinary_c.so
are designed to be thread safe. Setting up of the store structure, which can be shared among threads (e.g. when called by binary_c-python
), is protected by libpthread mutex locks. These locks are not active is libpthread is not available, in which case it is up to the user to make sure their process is calling binary_c
in a thread-safe manner.
9.5.9 NaN (not a number) checks¶
If NANCHECKS is defined, you can use the Nancheck(X) macro to test whether X is NaN. Note that checking for NaNs is computationally expensive, and you normally (once you trust your code) want NANCHECKS to be undefined. If a NaN is detected, binary_c
will stop with an error.
9.6 The binary_c evolution algorithm¶
The main time-evolution algorithm for each stellar system is controlled by evolve_system_binary_c(). Here I describe features, rather than simply go through the code.
- Time is simulated in timesteps of length (Sec. 9.7).
- Stellar structure is computed at time using the algorithm of your choice (Section 9.8). This happens in update_system_by_dt().
- During the timestep, derivatives of the system variables are calculated on the assumption that evolution is “smooth”. Variables that change smoothly, e.g. mass or orbital changes changing because of winds or RLOF, are updated for using an integrator.
- If the system changes suddenly as a result of stellar evolution or orbital changes, e.g. common-envelope evolution or a supernova occurs, an event is queued (Section 9.12).
- Checks are performed to make sure was short enough to resolve smooth changes to the system and that some events, e.g. start of RLOF and supernovae, are resolved as accurately as possible. If not, the timestep is rejected and is shortened if possible.
- After the “smooth” integration is complete, the events are triggered and the system updated as required.
- A new is computed (Sec. 9.7) and evolution continues until both stars are massless, or the maximum time or maximum model number is reached.
9.7 Timestep calculation¶
The binary_c
timestepping algorithm aims to smoothly, but efficiently, evolve your binary-star systems in time while maintaining a reasonable level of accuracy. The subroutine stellar_timestep sets the timestep for each star and/or the binary system as a whole. Usually, timesteps relate a change in variable
to its time derivative
and perhaps also its second derivative
, such that the timestep related to process
is,
where the multipliers
to resolve changes in
. The smallest of the
is then the recommended timestep for the star (and the smaller of the two for each star is usually the binary_c
timestep). The physical processes are labelled by integers
which are given human-readable macros (that you should use) in timestep.h e.g. DT_LIMIT_BLUE_STRAGGLER or DT_LIMIT_TPAGB_NUCSYN_INTERPULSE. The default multipliers corresponding to
are set in timestep_set_default_multipliers. You can set the timestep multipliers through command-line arguments, e.g. timestep_multiplier44 corresponds to DT_LIMIT_TIDES, because in timestep.h we have
#define DT_LIMIT_TIDES 44If you want to know what is limiting the timestep, the easiest way is to uncomment the linewhich is near the bottom of the stellar_timestep function. This will output, on every timestep, the timestep for each star and which limiter gave the smallest timestep.
#define ___LOGGING9.7.1 Fixed timesteps / timestep triggers¶
Often you will want to output at a given fixed timestep, e.g. every
. You can do this by added a macro to the list of fixed timesteps in timestep.h and increasing the NUMBER_OF_FIXED_TIMESTEPS by one to match, e.g. to have output every
after
, we call this scheme “MEGAYEAR”, in timestep.h you should have something like,then in setup_fixed_timesteps define the properties of your fixed timestep scheme, e.g.,You can also have fixed intervals of logarithmic time by settings t->logarithmic to TRUE.
#define FIXED_TIMESTEP_YIELDS 0
#define FIXED_TIMESTEP_MEGAYEAR 1
#define NUMBER_OF_FIXED_TIMESTEPS 2 t = &stardata->model.fixed_timesteps[FIXED_TIMESTEP_MEGAYEAR];
t->enabled = TRUE; // enable it
t->begin = 10.0; // start at 10Myr
t->end = stardata->model.max_evolution_time; // end at the end of evolution
t->step = 1.0; // step is 1Myr
t->next = t->begin + t->step; // next should be at the start + 1 Myr
t->logarithmic = FALSE; // do not use logarithmic times
t->final = TRUE; // do log on the final timestep
t->previous_trigger = t->previous_test = t->begin; // set triggerTo test whether your trigger has been activated, use code like the following.
const Boolean triggered = timestep_fixed_trigger(stardata,
FIXED_TIMESTEP_MEGAYEAR);
if(triggered == TRUE)
{
/* output stuff */
}9.8 Stellar structure computation in binary_c ¶
The stellar structure algorithm is not described here, but currently you can choose from either BSE and MINT. The code to determine which structure algorithm to choose is implemented in interface_stellar_structure.c and you can choose with the argument stardata->preferences->stellar_structure_algorithm:
- STELLAR_STRUCTURE_ALGORITHM_MODIFIED_BSE
- binary_c ’s version of BSE (default)
- STELLAR_STRUCTURE_ALGORITHM_NONE
- Do nothing!
- STELLAR_STRUCTURE_ALGORITHM_EXTERNAL_FUNCTION
- Use an external function (might be handy if MESA ever sorts out an API?), see Section 9.13.2 for details.
- STELLAR_STRUCTURE_ALGORITHM_MINT
- The next-generation MINT library (work in development).
9.9 Derivatives in binary_c ¶
Once the stellar structure is computed, it is relatively straightforward to compute rates of change of mass and angular momentum for both the individual stars and the binary system as a whole. These are stored in two arrays:
- stardata->star[k].derivative[n] where k is the star number and n is the derivative number. These are defined in STELLAR_DERIVATIVES_LIST in binary_c_derivatives.def.
- stardata->model.derivative[n] where n is the derivative number. These are defined in SYSTEM_DERIVATIVES_LIST in binary_c_derivatives.def.
You may want to debug the derivatives, in which case you can either:
- Set stardata->preferences->derivative_logging to True
- Call
show_derivatives(stardata);
9.10 Time integration ¶
binary_c
has, at the time of writing, RK2, RK4 and a (possibly buggy) predictor-corrector are alternatives, although the forward Euler is still the standard and fastest
11
. You can change the stardata->preferences->solver to SOLVER_FORWARD_EULER (default), SOLVER_RK2, SOLVER_RK4 or SOLVER_PREDICTOR_CORRECTOR.Forward Euler is standard except in the tidal calculations, some of which are calculated analytically, then linear derivatives are computed from these assuming everything else (stellar properties, etc.) in a hybrid scheme to avoid numerical instability.
Please note: most testing uses the forward Euler scheme, so please bear with me if you find a bug that affects one of the other schemes.
9.11 Timestep rejection¶
Each derivative listed in binary_c_derivatives.def can have a “check function” associated with it. These will check, say, that the mass or angular momentum remains positive. When something goes wrong, the timestep is rejected. In practice, this usually means that the previous timestep’s stardata is restored,
is halved, and evolution is restarted.
This goes wrong when
(set in stardata->preferences->minimum_timestep, units are Myr). When this happens we can do one of a few things, depending on the setting of stardata->preferences->cannot_shorten_timestep_policy
- CANNOT_SHORTEN_RESTORE_AND_TRY_EVENTS
- This restores the previous stardata, hence the masses and orbital variables, but still tries to run any events (such as stellar merging) that were triggered. This is, at the time of writing, the default.
- CANNOT_SHORTEN_CONTINUE
- This just carries on with a short timestep, ignoring the numerical problems. Variables that fail their check function are not updated, so will be out of date, however they will be (at least) physical (e.g. not a negative mass).
- CANNOT_SHORTEN_FAIL
- This causes an error to be triggered and evolution halted. If you are being careful, you probably want to do this.
9.12 Events¶
Starting from 2.0pre33 binary_c
has an events subsystem. Events are stored on an event stack and then processed at the end of the timestep, if it is a successful timestep. Events are things that happen to your stellar system on timescales that are too short to be modelled, e.g. common-envelope evolution or supernovae.
9.12.1 Event processing order and system-wide unique events¶
Events are processed in the order of their definition in events.def.
Any events marked as unique in events.def is the only event processed in a timestep. This applies particularly to common-envelopes, contact systems and unstable mass transfer (that may lead to mergers). However, unique events can themselves set events (e.g. common-envelope evolution sets a supernova event). These events are processed.
9.12.2 Queueing an event on the event stack¶
Events are added with the Add_new_event macro. This returns an integer which is the event number, if greater than or equal to zero, its index number on the event stack. If the integer is BINARY_C_EVENT_DENIED (which is -1 so can never be an index) then the event has, for some reason, been refused.
The Add_new_event macro call takes a number of arguments:
- stardata: the usual pointer to a stardata struct
- event_type: an integer identifying the event type. There are defined in events_macros.h
- event_handler_function: this is a pointer to a function to be called when the event is triggered. This is required to be non-NULL.
- erase_event_handler_function: this is a pointer to a function to be called when the event is erased. Ignored if NULL.
- event_data: this is a void* pointer, i.e. it is of whatever type you want it to be (your handler function should know), to data to be sent to the handler function. This can be NULL.
- unique: a Boolean specifying whether this event is one of a kind, or not. For example there can only be one common envelope per timestep, so
unique==TRUE, but there could be more than one supernova, sounique==FALSE.
The calling function should check the return value, and clean up any memory if required after a denial. For example, the following is the code to initiate dynamical common envelope evolution in the RLOF routines.
struct binary_c_new_common_envelope_event_t * event_data =
Malloc(sizeof(struct binary_c_new_common_envelope_event_t));
if(Add_new_event(stardata,
BINARY_C_EVENT_COMMON_ENVELOPE,
&common_envelope_event_handler,
NULL,
event_data,
UNIQUE_EVENT) == BINARY_C_EVENT_DENIED)
{
Dprint("not allowed an event :(\n");
Safe_free(event_data);
}
else
{
event_data->donor = donor;
event_data->accretor = accretor;
Dprint("added event!\n");
}9.12.3 Testing the event stack¶
- Call the events_pending function to return TRUE if there are events pending, FALSE otherwise.
const Boolean x = events_pending(stardata); - Call events_pending_of_type to return TRUE if there are events of a given type pending, FALSE otherwise.
const Boolean y = events_pending_of_type(stardata,BINARY_C_EVENT_COMMON_ENVELOPE); - Call event_stack_string to return a char* string describing the stack, suitable for logging and/or debugging. You need to Safe_free() the string.
char * evstring = event_stack_string(stardata); printf("Event stack: %s\n",evstring); Safe_free(evstring);
9.12.4 Erase the stack¶
The entire stack can be deleted by calling erase_events. The void* data associated with each event is freed.
erase_events(stardata);You can also call erase_events_of_typewhich will erase all events of given type except the event except. If the type is -1 then events of any type are removed, except except. If except is NULL then all events of the given type are removed.
erase_events_of_type(stardata,type,except);You can erase an event without altering the event stack by callingbut beware that this will mess up the stack and binary_c
is likely to be very confused.
erase_event(stardata,&event);When events are erased, the optional erase_event_handler_function() function is called, with the same arguments as the event handler function. You can use this to clean up any allocated memory.
9.12.5 Catch events¶
At the end of each (successful) timestep, catch_events is called. This function loops through the stack, triggering each event by calling the handler function and sending it the event data as well as stardata. Event data is freed automatically after the event is triggered, as is the event itself, so if you want to save anything for later logging, use the event log stack (see Sec. 9.12.7).
9.12.6 Event handler functions¶
The event handler functions should look like the following, again using the common-envelope code as an example.
Event_handler_function common_envelope_event_handler(void * eventp,
struct stardata_t * stardata,
void * data)
{
/* a pointer to the event */
struct binary_c_event_t * const event = eventp;
/* a pointer to the event data */
struct binary_c_new_common_envelope_event_t * const event_data =
(struct binary_c_new_common_envelope_event_t*) data;
/* information stored in the event data */
struct star_t * const donor = event_data->donor;
struct star_t * const accretor = event_data->accretor;
/* ... now do stuff with donor and accretor ... */9.12.7 Event logging and log stack¶
You can add data on the event-log stack. This can be accessed until the end of the timestep. Use the Add_event_log_data macro to do this,
Add_event_log_data(TYPE,LABEL,DATA,FREEFUNC)where TYPE is the event type number (see events.def), LABEL is an integer label which you define or ignore, DATA is a pointer to a data structure, FREEFUNC is a function to free the data, or NULL if it can be freed using Safe_free() (i.e. C’s free()). You can set FREEFUNC to &free_star or &free_stardata to free a star_t or stardata_t struct, respectively.
During logging, you can access event log data with a loop like this, where Next_event_log() looks for any log data of the type list given it
struct binary_c_event_log_t * elog = NULL;
while((elog = Next_event_log(BINARY_C_EVENT_SUPERNOVA0, BINARY_C_EVENT_SUPERNOVA1)))
{
// do stuff with elog
}If you would like the data to be reprocessed, you should set elog->processed to FALSE, but beware loops like the above will continue forever. It is best to thus process log data once, but you can always save the pointers and set them manually.
At the end of a timestep, after all evolution and logging is finished, event data is freed automatically.
9.12.8 Events through the API¶
You have access to some of the events functionality through the binary_c
API.
- binary_c_catch_events
- This calls catch_events()
- binary_c_events_replace_handler_functions
- This allows you to replace a handler function on a particular event type with your own handler function.
- binary_c_generic_event_handler
- This calls generic_event_handler() which in turn calls the event handler that binary_c would use. This is useful if you are catching an event yourself but in addition want binary_c to do what it normally does.
- binary_c_erase_events
- This calls erase_events()
9.13 Function hooks¶
There are a number of locations in binary_c
where you can call a function hook. You can set these functions from your code that uses the binary_c
API, or from another language e.g. Python.
9.13.1 Standard hooks¶
The following hooks take a single stardata structure as their only argument. These are function pointers set in the array stardata->preferences->function_hooks[], which are usually each NULL hence ignored. These hooks should be called using the Call_function_hook() macro, e.g.(except in catch_events.c which is a bit special).
Call_function_hook(extra_update_binary_star_variables);The indices to the stardata->preferences->function_hooks[] array are (as defined in binary_c_function_hooks.def):
- BINARY_C_HOOK_catch_events
- alternative function to catch events, e.g. to do event logging.
- BINARY_C_HOOK_custom_output
- called after a timestep to do extra logging.
- BINARY_C_HOOK_extra_apply_derivatives
- called by the solver to compute more derivatives.
- BINARY_C_HOOK_extra_calculate_derivatives
- called during time evolution to compute more derivatives.
- BINARY_C_HOOK_extra_ensemble
- called in the ensemble_log to do extra ensemble calculations.
- BINARY_C_HOOK_extra_update_binary_star_variables
- called to compute further binary-star variables.
- BINARY_C_HOOK_post_time_evolution
- called just after time evolution of the system has been done, but before rejection is tested.
- BINARY_C_HOOK_pre_time_evolution
- called at the start of each timestep just before time evolution begins.
If you require an extra hook, please just ask.
Please note: in previous versions of binary_c
, the above hooks were called …_function, e.g., post_time_evolution_function, and were set individually, not grouped in an array. In the current version (2.2.2) of binary_c
the old …_function pointers still exist but are simply copied from the stardata->preferences->function_hooks[] array. The …_function variables are marked as deprecated, which should trigger compiler warnings in any code that uses them, and will be remove in future versions of binary_c
.
9.13.2 Extra, non-standard function hooks¶
There are a few non-standard function hooks that take more than just a stardata.
- stellar_structure_hook
- used when a custom stellar structure algorithm is set (see Sec. 9.8). This function takes a caller id number and a variable number of arguments.
int (*stellar_structure_hook)(const Caller_id caller_id, ...); - extra_stellar_evolution_hook
- this is a function that computes extra stellar evolution after update_system_by_dt() does its work.
void (*extra_stellar_evolution_hook)(struct stardata_t * stardata, const Evolution_system_type system_type); - extra_update_binary_star_hook
- this is a function that computes extra binary evolution after update_system_by_dt() does its work.
void (*custom_supernova_kick_hook)(struct stardata_t * const stardata, struct stardata_t * const pre_explosion_stardata, struct star_t * const star, struct star_t * const pre_explosion_star);
9.14 Code layout, header files, flow¶
The code is split into a series of directories (Section 9.17). Some header file information is in 10.
9.14.1 API¶
You can build binary_c
as a shared library, and use the API interface. The functions which do this are in this directory. See Section 8 for details.
9.14.2 batchmode¶
The batch mode functions handle the use of binary_c
in an interaction command-line batch mode.
9.14.3 binary_star_functions¶
9.14.4 buffering¶
These functions provide an interface other software, e.g. binary_c-python
, to improve performance. When you use the Printf macro, rather than C’s native printf routine, you are using the routines in here to put data into a memory buffer which is then sent to binary_c-python
for processing and statistical analysis.
When you output with Printf your output either goes into a buffer or to the screen, according to the parameter stardata->preferences->internal_buffering. You can access the buffer either through the internal buffer_info function, or the API’s binary_c_buffer_info function.
- INTERNAL_BUFFERING_OFF
- Output to stdout (no buffer is stored).
- INTERNAL_BUFFERING_PRINT
- Store in the buffer and dump the buffer’s contents to stdout at the end of each timestep.
- INTERNAL_BUFFERING_STORE
- Store in the buffer for later use (this is probably what you want if you are using the API).
9.14.5 common_envelope¶
Common envelope evolution is dealt with in here. At present there is only the BSE algorithm, but you could put your own in here too.
9.14.6 debug¶
This contains various debugging functions, such as debug_fprintf which is called when you put Dprint statements into binary_c
. The backtrace functionality is also in this directory, as is the show_stardata function which allows you to output, in a readable way, the contents of a stardata structure. Given this you can compare one structure’s contents to another quickly and easily.
9.14.7 disc¶
Work in progress, please ask RGI for details.
9.14.8 envelope_intgeration¶
Experimental code.
9.14.9 equation_of_state¶
Experimental code.
9.14.10 events¶
See section 9.12.
9.14.11 evolution¶
The time integration, i.e. evolution, of the binary system. This contains the logic flow of the binary_c
code. Of interest to the general user are:
- evolve_system_binary_c is the main time loop which sets up the system at its initiation, loops over time (at each timestep calling evolution, see below) and then cleans up when things are all finished.
- evolution The main time-evolution function. This calls the appropriate integration scheme to further the binary system under investigation in time. The default scheme is forward-Euler, but Runge-Kutta 2nd and 4th order are also available. The function evolution_step in turn, for all the schemes, calls the other parts of binary_c that do all the appropriate physics.
9.14.12 file¶
File input/output code. binary_c
provides a custom file output routine which can limit output by size of the file, as well as output filtering routines.
9.14.13 galactic¶
Experimental! A set of routines to calculate apparent and bolometric luminosities, and develop a model of galactic coordinates. It’s not clear that we should be even doing this in binary_c
…
9.14.14 libmemoize¶
This is a copy of RGI’s memoizing library libmemoize. The idea is that repeated calls to a function with the same arguments are automatically cached so that the function is actually only called once. Note: if you have libmemoize properly installed on your system, e.g. in $HOME/lib or /usr/local/lib, which is what you should do, then the installed version is used. The version in binary_c
is a backup version only, and may lack the latest features.
9.14.15 librinterpolate¶
This is a copy of RGI’s librinterpolate linear interpolation library. If you have librinterpolate installed properly, e.g. in $HOME/lib or /usr/local/lib, which is what you should do, then the version in binary_c
is ignored. Note: librinterpolate is required for binary_c-python
.
9.14.16 logging¶
Contains some functions used to output either to the screen or a file. Not very interesting but vital if you are to get anything out of binary_c
.
- log_every_timestep which is called every (successful) timestep to output the current state of the star. This is where you want to put your logging code! Please remember: when logging use the Printf macro, not C’s printf-type function calls.
9.14.17 maths¶
Contains a selection of routines to do some mathematical tasks that are useful to binary_c
, many of these routines are wrappers to GSL functions. There are not-a-number (NaN) checking routines, random number generators, a Kaps-Rentrop solver, a generic Brent minimizer, and the apply_derivative function which is used by evolution to integrate numerical derivatives at each timestep.
- Some of the code is experimental so probably not used.
- Anything you put in this directory must be free and freely distributable software. There are no routines from Numerical Recipes in C because these are not free software.
9.14.18 memory¶
In here reside binary_c
’s memory allocation and freeing (garbage collection) routines.
9.14.19 misc¶
Routines that don’t go anywhere else. At the moment this contains nothing.
9.14.20 nucsyn¶
See section 9.15.
9.14.21 opacity¶
Experimental.
9.14.22 orbit¶
Routines which calculate orbital properties go in here.
9.14.23 perl¶
Useful perl scripts, e.g. to rename variables or run many valgrinds.
9.14.24 python¶
Python scripts, e.g. to access the API through Python, are in here.
9.14.25 RLOF¶
First, there is the question of when
. Because of limited time resolution, if RLOF happens then it starts with
(the code overshoots the
time). In the original BSE code, and still in binary_c
if you set RLOF_interpolation_method=RLOF_INTERPOLATION_BSE(=1), interpolation in time is performed to find
to within some threshold (usually 2%). However, this means taking negative timesteps, which plays havoc with logging and nucleosynthesis algorithms.
In the latest binary_c
, a simpler (albeit slower) algorithm is used which rejects the evolution when
The previous stardata is loaded over the top of the current stardata, and the timestep is halved. Evolution then continues until
, to within a small threshold (e.g.
), always with a positive timestep.
RLOF itself is followed according to one of a number of algorithms. First, the system is tested for the stability of RLOF (RLOF_stability_tests). If RLOF is unstable, a merger or common envelope usually entails. Second, if the RLOF is stable, there are several methods for calculating the mass transfer rate. The formulaic approach assumes that for a given
there is a function,
, which gives the mass transfer rate. This is numerically quite stable. The alternative adpative approach consists of iterating to find a solution to
. This is more exact, but requires more calculation steps. Usually, the two methods give similar answers, but if mass transfer is particularly fast, e.g. in massive stars, this may not be the case.
9.14.26 setup¶
This sets the code up because set_up_variables is called by the main function. It reads in the command line arguments and sets them to variables.
The parse_arguments function takes command line arguments and puts them into (in particular) the preferences structure. This function is very useful if you want to put in your own arguments, which should go into cmd_line_args_list.def.
9.14.27 signals¶
Unix/Linux uses signals to communicate with running programs. Code in here allows you to catch signals, as well as catching (and trapping) segmentation faults which is very useful for debugging (e.g. with gdb and/or valgrind).
9.14.28 single_star_functions¶
Many functions which only affect single star, or detached binary, evolution are in this directory.
9.14.29 spectra¶
Functions in here link stars, through their temperature and luminosity, to spectra. At present only a blackbody spectrum is supported, but the algorithm for calculating the blackbody flux in regions of wavelength parameter space is fast and accurate.
9.14.30 stellar_colours¶
This contains some routines to calculate stellar colours, which may or may not be reliable.
9.14.31 stellar_structure¶
Sets up a new_structure struct, and passes this to the appropriate stellar structure calculation code. Currently only stellar_structure_BSE is available, but in future different codes may arise.
stellar_structure_BSE is based on the hrdiag function of SSE/BSE. It computes the stellar structure variables at a given time. In addition, it handles supernova explosions and kicks. Note that this functionality may eventually be removed from the stellar_structure directory.
9.14.32 stellar_timescales¶
This set of functions calculates the timescales required by stellar_evolution, as in the SSE/BSE stellar evolution package (in which it is the function star.f, and in binary_c
V1.x it is calc_lum_and_evol_time in claet).
9.14.33 string¶
Functions to manipulate strings go in here, including binary_c_asprintf (to replace asprintf if Gnu or libbsd’s version is not available) and chomp (to remove newlines at the end of a string, identical to Perl’s chomp).
9.14.34 supernovae¶
Functions which deal with supernovae, e.g. kicks, NS/BH mass as a function of progentior, etc. Note that supernovae are dealt with at the end of a timestep as an event (see section 9.12).
9.14.35 tables¶
Various tables of data, used by librinterpolate, are included in binary_c
. This directory contains the data for them and the various setup functions. In future, this data may be held elsewhere and its location accessed through an environment variable.
9.14.36 timers¶
These are functions which start and stop the ticks counters. They are used to measure CPU time use, i.e. profiling of the code. Note that there are many ways to profile (including e.g. cachegrind and callgrind, functions of valgrind, and the ever reliable gprof).
9.14.37 timestep¶
Routines for calculating the stellar timestep, see the function stellar_timestep for details.
9.14.38 triple_star_functions¶
Experimental! As the name suggests, these are functions to calculate the various physics in triple stars.
9.14.39 wind¶
Routines for calculating the stellar wind loss rate. Note that the main function that calculates the wind mass-loss rate is actually in src/single_star_functions/calc_stellar_wind_mass_loss.c but that just calls wind_mass_loss_rate which is in this directory.
9.14.40 zfuncs¶
The so called “metallicity functions” of BSE i.e. the many fits to
,
,
etc. as a function of
and
(and perhaps other parameters). These are lots of tiny functions which contain fitting formulae.
Lately I have added some new functions, such as mc_1DUP (the core mass at which first dredge up occurs), fphase (the fractional age in a given stellar evolution phase), rwd and lwd (radius and luminosity of a white dwarf) etc. This seems a reasonable location for storing small, useful functions.
Please note that I have optimized these functions to the hilt because they are called very often.
9.15 nucsyn¶
The nucleosynthesis functions are in a directory of their own. It contains the functions which deal with the nucleosynthesis part of the code which runs in parallel to SSE/BSE. That is not to say that all the nucleosynthesis is done here, but most of it is.
To enable nucleosynthesis in the code you must
#define NUCSYNin binary_c_parameters.h. It is vitally important that if you add anything to the nucleosynthesis code you enclose it in something like
#ifdef NUCSYN
...
#endif /* NUCSYN */so that if nucleosynthesis is not required it can be turned off.
There are then further options in nucsyn_parameters.h (see section 10).
NOTE! Every function in the nucsyn library has nucsyn prepended to the function name - please maintain this convention!
9.15.1 Header files and isotope arrays¶
All abundances are stored as mass fractions when the array is called X…, number densities are referred to as N…. The index for each array ranges from
to ISOTOPE_ARRAY_SIZE which is defined in nucsyn_isotopes.h however you should NEVER manually access the array by number, e.g. you should use the predefined macros referring to each isotope in nucsyn_isotopes.h and nucsyn_isotope_list.h. For example, XC12 is defined like this
X[0]=0.5;12
,Actually, in a modern binary_c
, it is defined to be one more than the previous isotope. This is just an integer, of course, and you don’t care what that integer is.
#define XC12 2X[XC12]=0.5; /* or, similarly */ N[XC12]=1e-8;
Why is this an advantage? It is very useful to be able to pull isotopes out which are not of interest (this speeds up the code) without breaking all the others, the historical development of the code (
,
and CNO came first) is not a problem and the addition of new nuclei is easy (but remember section 9.15.2). It also makes the code bloody easy to read since it is painfully obvious which isotope you are referring to! This is important late at night after too much coffee (or other drink!).
9.15.2 Setup functions¶
nucsyn_set_nuc_masses sets the nuclear masses (in grams) and atomic numbers. If you add an isotope to nucsyn_isotopes.h (see section 9.15.1) you MUST change this function to set the nuclear mass or atomic number. If you do not then the number will be undefined and strange things will happen even though your nice new code looks fine (and valgrind will immediately fail because you’ll be reading from undefined memory).
nucsyn_initial_abundances is obviously important because it defines your initial abundance mix, usually as a function of the metallicity.
9.15.3 First and Second Dredge-up¶
First and second dredge-up are handled by the functions nucsyn_set_1st_dup_abunds and nucsyn_set_2nd_dup_abunds which perturb the surface abundances. There may be problems in binaries because the evolution is different to single stars, but I try to take this into account by scaling the CNO abundances to whatever the stellar CNO abundance is. Thanks to Evert Glebbeek and Richard Stancliffe for helping out with this, the results will be published in one of our CEMP papers soon.
9.15.4 TPAGB functions (3rd dredge-up and HBB)¶
The first section of the library to be written was the synthetic TPAGB evolution (see , 2004). This is controlled by the function nucsyn_tpagb. The function determines whether the next thermal pulse has been reached by the star and if so it does third dredge-up (and perhaps there’s some hot-bottom burning [HBB]).
On the first pulse (when the function is first called for the star, actually if
num_thermal_pulses < 0, which is the case for any stellar type other than TPAGB) the function nucsyn_init_first_pulse is called which sets a few things like the interpulse period and
for dredge-up.For subsequent timesteps the nucsyn_tpagb function calls nucsyn_tpagb_H_shell_burn to burn the hydrogen shell during the interpulse period and save the amount of core mass growth
.
There is then a check to see if the star is hot enough for HBB – this is done by fitting the temperature (see nucsyn_set_hbb_conditions, nucsyn_hbbtmax and nucsyn_tpagb_rhomax) to mass and metallicity. If so the nucsyn_hbb function is called. The free parameters associated with HBB (, 2004) are set in nucsyn_set_tpagb_free_parameters (these are the burn times, mixing fractions etc.).
If the next pulse is reached then nucsyn_third_dredge_up is called to deal with third dredge-up. This dredges up a mass
and mixes it with the envelope. The abundances of the dredged-up material are set in nucsyn_set_third_dredgeup_abunds (and nucsyn_s_process for s-process elements).
Version 1.2 of binary_c
included an option to evolve “super AGB” (STPAGB) stars but this has since been deprecated.
9.15.5 Hot-Bottom Burning¶
While this sounds painful, really it’s not! HBB is the process where the convective zone in a TPAGB star reaches down into the hydrogen burning shell. This occurs in
stars (for
, lower masses for lower metallicity). I have two burning routines which can deal with this:
- The original analytic routine. This uses analytic solutions to the CN, ON, NeNa and MgAl cycles, together with some approximate fudges to join them into the CNO and NeNaMgAl cycles, to solve for the abundances. This is fast but sometimes, when used outside the range of the approximations, very unstable.
- The new numerical solver. This uses a 4th-order implict (Kaps-Rentrop) scheme to solve for the abundances as a function of time. It does not depend on approximations, and currently burns the -chain, CNO cycles (hot or cold) and the full NeNa/MgAl chains/cycles. In theory it can be extended to any nuclear network (although it is designed for small networks – it will get very slow with larger networks). It turns out that, after much code optimization, the numerical solver is about as fast as the analytic solver! I think this is because to solve numerically requires additions, subtractions, multiplications and divisions, while analytic solutions require lots of exponentials. However, whether the numerical solver quickly converges on a result depends on the initial timestep. Be careful with that, I have a number of schemes which can improve this.
9.15.6 nucsyn_WR¶
This is a set of phenomenological fits to Lynnette Dray’s models for massive stars and helium star remnants. It is self-contained (see the details above and in the function) and contains useful stuff regarding logging of O/B and WR stars. I recently updated it to use tabular lookups instead of fitting functions.
The latest version includes tables from Richard Stancliffe which follow all isotopes, not just elemental CNO and H, He. Thanks Richard!
9.15.7 The -process¶
9.15.8 Winds and Mixing¶
Colliding winds and the like are a complicated business! nucsyn_update_abundances is called when to deal with this. The function is well commented so for details please refer to it but briefly it takes the wind loss from each star and the amount of that accreted by the companion, determines whether the accreted matter should reach the surface (by the factor set in nucsyn_choose_wind_mixing_factor) or not and if so mixes it in or makes a new accretion layer on the surface. It also yields the wind loss by a call to nucsyn_calc_yields and the mass accreted by a similar call but with a negative number. Note: mass is removed from the surface of the star by the function nucsyn_remove_dm_from_surface so that it is preferentially removed from the accretion layer rather than the stellar envelope. Convective stars have no accretion layer, if one is present a call to nucsyn_mix_accretion_layer_and_envelope soon removes it.
9.15.9 Explosions (supernovae and novae)¶
9.15.10 Yield calculations¶
The calls to nucsyn_calc_yields modify the arrays Xyield in the star structures. These contain the mass of material of each isotope lost by the star, so if nucsyn_calc_yields is called for (say) wind loss by an amount
with abundances
then the amount of mass lost as isotope
is
which is added to the appropriate Xyield array item
. This is a simple definition for single stars but gets complicated in binaries because wind/RLOF accretion takes place. In that case the same nucsyn_calc_yields function is called but for a negative mass
. In this way mass is conserved because the other star yields the
(or perhaps more mass if some is lost from the system). The total mass lost from the system is then just the sum of the Xyield for both stars.
The array mpyield stores the values of
, the enhancement of isotope
relative to the ZAMS abundance and divided by the initial mass (note use pms_mass not ZAMS_mass since the latter is redefined by accretion processes).
Binary system yields are easy to calculate because they are just the sum of both stars’ yields, this is done in nucsyn_binary_yield. The appropriate
yields are more difficult to define but there is an attempt.
9.15.11 Logging and minor functions¶
There are numerous logging functions for debugging and general pretty-picture-manufacture, e.g. nucsyn_log, nucsyn_long_log, nucsyn_short_log, nucsyn_j_log. Most of these are activated or deactivated in nucsyn_log.h. Other minor functions: nucsyn_totalX calculates the total mass fraction (or actually the total sum of array elements), nucsyn_square_bracket calculates an abundance in “square bracket notation” by mass fraction (should it be by number?); nucsyn_mix_shells mixes two isotope arrays together (very useful!) there are the other mixing functions nucsyn_dilute_shell and nucsyn_dilulte_shell_to which are similarly useful; nucsyn_radioactive_decay decays a few isotopes – it is by no means exhaustive, there may be other isotopes you wish to place in here but it’s easy to extend; nucsyn_mole_fraction converts an array of mass fractions to mole fractions, perhaps useful for the square bracket logging?
9.15.12 Other stellar remnants¶
Some stellar types are not dealt with by nucleosynthesis. There include WDs (nucsyn_set_WD_abunds), which are assumed to: HeWD 100%
, COWD 80%
and 20%
while ONeWD 80%
and 20%
. This could be improved (to take into account, say, the heavier metals) but note that any accretion onto the surface from a non-degenerate companion will mask the above abundances (since an accretion layer will form on the surface unless there are novae) and the business of accretion onto WDs is very complicated indeed.
NSs and BHs are remnants with their abundances set in nucsyn_set_remnant_abunds are assumed to be all neutrons with
Xsurf[Xn]=1.0;9.16 Coding style¶
binary_c
C code follows a particular style to which you should adhere. More reading at https://gcc.gnu.org/onlinedocs/gcc/Standards.html.
- We require that the compiler supports C11 constructs with GNU extensions. This means GCC 4.9 or later. Our standard is equivalent to the GCC compiler flag c_std=gnu11.
- The binary_c
style is based on the Allman style with a few minor changes.
- This means for and while loops are like this
for(i=0; i<10; i++) { ... } - If statements are like thisplease be explicit: do not just use
if(x == TRUE) { ... }if(x)except in testing. Please use spaces around operators, soif(x == TRUE) // good if(x==TRUE) // bad - Note that there is no space after the constructor (for, if, …).
for (i=0; i<10; i++) // wrong! { ... } - Try to keep lines short, shorter than 80 characters if possible.
/* this is good */ printf("got nstrings = %ld : %s, %s, %s...\n", nstrings, nstrings >= 1 ? strings[0] : "", nstrings >= 2 ? strings[1] : "", nstrings >= 3 ? strings[2] : ""); /* this is bad */ printf("got nstrings = %ld : %s, %s, %s...\n",nstrings,nstrings >= 1 ? strings[0] : "",nstrings >= 2 ? strings[1] : "",nstrings >= 3 ? strings[2] : ""); - All warnings from the compiler are considered to be bugs. We build with -Wpedantic for a reason.
- This means for and while loops are like this
- Indent with four spaces (emacs indents C like this automatically)
{ bad bad bad good } - Comments should be multi-lined for enhanced legibilitythe exception is after
/* * This is a good comment */ /* This is an ugly comment, ok for temporary work */ // This is a bad comment#endife.g.,#endif // This is a good comment
9.16.1 Macros¶
C preprocessor macros are a very powerful way to make code more readable, or less, depending on their use, hence binary_c
has strict rules for their use.
- Macros used as flags should use CAPTIALS and, when used in #ifdef … #endif pairs, you should include a comment at the end of the pair to say specify the opening macro, for example.
#define FLAG_MACRO #ifdef FLAG_MACRO ... do stuff #endif // FLAG_MACRO
- Constant macros should use upper case, e.g.,
#define CONSTANT_MACRO 3 - Function macros should be named with the first character in upper case, the rest in lower case, and when you address arguments remember to wrap them in parentheses, e.g.,exceptions to this are the macros used for stellar types, PRINTF which is just mapped to Printf for backward compatibility, and macros such as likley and unlikley which are kept in lower case to match external code (in this case the Linux kernel).
#define Pow2(X) ((X)*(X)) #define Other_star(K) ((K)==0 ? 1 : 0)
Most function macros are in binary_c_function_macros.h. - You should NOT use X as a function macro name. binary_c uses X-macros, so requires X to be free for those, not for your work. If you do use X as a function macro, expect it to be destroyed randomly.
- Macros which are used only locally, and variables used in macro expressions, should be prefixed with two underscores, as is standard in C.
#define __LOCAL_MACRO 1 - When comparing to TRUE and FALSE, please be explicit, i.e.
== TRUEor== FALSE, e.g.,if(vb == TRUE) { /* ... do something ... */ } - You are free to use GCC’s statement expressions (https://gcc.gnu.org/onlinedocs/gcc/Statement-Exprs.html) but please prefix them with
__extension__and wrap them inThe macro USE_GCC_EXTENSIONS may, or may not, be defined, depending on your compiler. With a modern GCC or Clang, it is, but please do not rely on this.#ifdef USE_GCC_EXTENSIONS ... /* the macro you want to use */ #else ... /* fallback code */ #endif // USE_GCC_EXTENSIONS
Note that some software used by binary_c now requires GCC extensions, such as libcdict. - Please use a macro that calls a macro should you require a temporary variable. In the example below, Max(A,B) is the macro that the use calls. This then calls another implementation macro passing, along with A and B, a unique LABEL string and the COUNTER (usually __COUNTER__ as provided by the compiler) which is a unique number. The implementation macro then does the work, constructing unique variable names from LABEL and COUNTER using __typeof__.
/* * this macro does the work but calculates (A) twice, so might * be inefficient if (A) is a function call. */ #define Max_macro(A,B) ((A)>(B) ? (A) : (B)) #ifdef USE_GCC_EXTENSIONS /* * An implementation statement expression that sets (A) * and (B) into temporary variabless so they are calculated * only once. */ #define Max_implementation(A,B,LABEL,COUNTER) \ __extension__ \ ({ \ __typeof__(A) Concat3(__a,LABEL,COUNTER) = (A); \ __typeof__(B) Concat3(__b,LABEL,COUNTER) = (B); \ Max_macro(Concat3(__a,LABEL,COUNTER), \ Concat3(__b,LABEL,COUNTER)); \ }) /* * The macro called by the user, sends the unique string "Max" * and __COUNTER__ to the implementation along with (unevaluated, * at this stage) A and B. */ #define Max(A,B) Max_implementation((A),(B),Max,__COUNTER__) #else /* * Fallback if GCC extensions are not available. */ #define Max(A,B) Max_macro((A),(B)) #endif // USE_GCC_EXTENSIONS
9.17 Directory structure¶
The main binary_c
directory contains a number of sub-directories.
- The src directory, which holds all the .c, .h and .def files which are the source code of binary_c .
- doc contains documentation.
- src/perl contains some useful Perl scripts.
- src/python contains Python scripts. These are mostly designed to work with binary_c-python and include the ensemble manager.
- src/inlists contains inlists for the ensemble manager.
- unit_tests contains unit testing components.
- meson contains scripts used by Meson during configuration.
- builddir contains the Meson/Ninja build information. You can delete this at any time, but you will have to rebuild everything from scratch if you do.
- triple contains triple-star extensions (work in progress).
- apitest contains API testing code.
9.18 Control scripts¶
I have a number of control scripts written in Perl or Python which test the code and output graphs and data for, e.g., AGB stars and WR stars (to compare to full evolution models), stellar yields etc. There might be some documentation here eventually… it all depends on whether you prefer writing your own scripts (that way you’ll learn how it all works) or just having a black-box that works (you can always look at the source code).
A very useful script is zipup which makes a file binary_c.zip containing this manual and all the source code.
top10 Advanced Configuration¶
There are three main C header files which affect how the binary_c
code is built: binary_c_code_options.h, binary_c_parameters.h and nucsyn/nucsyn_parameters.h. Some low-level configuration is also performed by the Meson build process.
10.1 Meson configuation¶
When you change something in binary_structures.h, or one of the other header files, you may have to reconfigure Meson because this in turn reruns make_showstruct.pl which builds code to show the contents of stardata_t structures.
10.2 binary_c-config¶
Many Unix-type commands have an associated *-config command which gives details of their build flags, version, build date etc. As of recently, so does binary_c
, so you can run,
binary_c-config help--cflags Show the flags which were used to build binary_c (same as --flags) --libs Show library linking information --libs_list Show library linking information as a space-separated list without -l --help Show this help and exit --version Show binary_c's version number. --full_version Show binary_c's full version string. --cc Show the C compiler used to build binary_c --cc_version Show the version of the C compiler used to build binary_c --ld Show the linker used to build binary_c --ldd Show binary_c's dependencies --incdirs Show binary_c's include dirs (for header files) --incdirs_list Show binary_c's include dirs (for header files) as a space-separated list without -I --libdirs Show binary_c's library search directories during build --libdirs_list Show binary_c's library search directories during build as a space separated list without -L --git_url Show the URL of binary_c's git source (if available) --git_branch Show the git branch being used (if available) --git_revision Show the revision of binary_c's git source (if available) --structs Show structure sizes --svn_url Show the URL of binary_c's svn source (if available) --svn_revision Show the revision of binary_c's svn source (if available) --build_date Show the date and time of binary_c's build --define_macros Show macros defined by -D... in the compiler flags (except -D__whatever__) --undef_macros Show macros undefined by -U... in the compiler flags (except -U__whatever__) --all_define_macros Show macros defined by -D... in the compiler flags --all_undef_macros Show macros undefined by -U... in the compiler flags --defaults Show binary_c's default settings --defaults_set Show the label of the current defaults set --tests Show the results of unit testing.
note that the double minus sign is optional (it can also be one minus sign, or none). For example,
$ binary_c-config define_macros -DOPERATING_SYSTEM=linux -DLINUX -DPOSIX -DLARGEFILE_SOURCE -DALIGNSIZE=8 -DCPUFREQ=4800 -DBINARY_C_SRC=/home/izzard/git/binary_c/src -DBINUTILS_VERSION=2.38 -DBFD_2_33 -D_FILE_OFFSET_BITS=64 -DFPU_CONTROL -DGIT_REVISION=6624:20230119:c5d02fd9c -DGIT_URL=git@gitlab.com:binary_c/binary_c.git -DGIT_BRANCH=master $ ./binary_c-config git_url git@gitlab.com:binary_c/binary_c.git $ binary_c-config version 2.2.3 $ ./binary_c-config git_revision "6624:20230119:c5d02fd9c" $ binary_c-config cflags -std=gnu18 -DOPERATING_SYSTEM=linux -DLINUX -DPOSIX -DLARGEFILE_SOURCE -DALIGNSIZE=8 -fstrict-aliasing -Wstrict-aliasing -g -Wno-sizeof-pointer-div -Wpedantic -Wshadow -Wno-variadic-macros -fstack-protector-all -rdynamic -fsignaling-nans -march=native -mtune=native -frounding-math -fno-stack-protector -ffloat-store -D__ACCURATE_BINARY_C__ -fno-finite-math-only -fasynchronous-unwind-tables -fvisibility=hidden -export-dynamic -O0 -DCPUFREQ=4800 -DBINARY_C_SRC=/home/izzard/git/binary_c/src -DBINUTILS_VERSION=2.38 -DBFD_2_33 -D_FILE_OFFSET_BITS=64 -D__HAVE_LINK_H -D__HAVE__VA_OPT__ -D__HAVE_GNU_QSORT_R -D__HAVE_NATIVE_EXP10 -D__HAVE_POSIX_FADVISE -DFPU_CONTROL -D__HAVE_ATTRIBUTE___RESTRICT____ -D__HAVE_ATTRIBUTE_ALLOC_SIZE__ -D__HAVE_ATTRIBUTE_AUTO_TYPE__ -D__HAVE_ATTRIBUTE_BUILTIN_EXPECT__ -D__HAVE_ATTRIBUTE_CONST__ -D__HAVE_ATTRIBUTE_DEPRECATED__ -D__HAVE_ATTRIBUTE_GNU_PRINTF__ -D__HAVE_ATTRIBUTE_HOT__ -D__HAVE_ATTRIBUTE_PACKED__ -D__HAVE_ATTRIBUTE_PURE__ -D__HAVE_ATTRIBUTE_MALLOC__ -D__HAVE_ATTRIBUTE_NONNULL__ -D__HAVE_ATTRIBUTE_NORETURN__ -D__HAVE_ATTRIBUTE_RETURNS_NONNULL__ -D__HAVE_ATTRIBUTE_UNUSED__ -DGIT_REVISION=6624:20230119:c5d02fd9c -DGIT_URL=git@gitlab.com:binary_c/binary_c.git -DGIT_BRANCH=master -D__HAVE_LIBC__ -D__HAVE_LIBCFITSIO__ -D__HAVE_LIBGSL__ -I/home/izzard/include -D__HAVE_LIBGSLCBLAS__ -D__HAVE_LIBDL__ -D__HAVE_LIBPTHREAD__ -D__HAVE_LIBUUID__ -D__HAVE_LIBZ__ -D__HAVE_LIBBFD__ -D__HAVE_LIBBSD__ -D__HAVE_LIBIBERTY__ -D__HAVE_LIBJEMALLOC__ -D__HAVE_LIBM__ -D__HAVE_LIBMEMOIZE__ -D__HAVE_LIBRINTERPOLATE__ -D__HAVE_LIBCDICT__ -D__HAVE_LIBUNWIND__ -D__HAVE_LIBBACKTRACE__ -D__HAVE_BACKTRACE_H__ -D__HAVE_IEEE754_H__ -D__HAVE_DRAND48__ -D__HAVE_HSEARCH_DATA__ -D__HAVE_MALLOC_H__ -D__HAVE_SETITIMER__ -D__HAVE_HAS_INCLUDE -D__HAVE_PKG_CONFIG__ -D__HAVE_VALGRIND__ -D__SHOW_STARDATA__ -D__DIFF_STARDATA__ -D__HAVE_LIBIBERTY_LIBIBERTYH__ -D__HAVE_BZCAT__ -D__HAVE_ZCAT__ -D__HAVE_7Z__ -O0
The binary_c-python
Python module makes extensive use of binary_c-config to determine which flags it should use to build its interface to libbinary_c
.
Note that the binary_c-config tool is actually a bash script that requires binary_c
to be built, and working tools such as grep, tr, sed, gawk and ldd. These are standard tools on most Unix systems. If binary_c
does not work, or you do not have (a reasonably modern) bash, something may fail.
10.3 meson -D…¶
Some options are set up by Meson and passed as -D… arguments to the compiler:
- LINUX is defined if you’re running Linux. This is useful for some timers and segfault catchers which only work with the Linux libraries.
- LARGEFILE_SOURCE and FILE_OFFSET_BITS were once useful for large output files on 64-bit machines (>2GB). This may no longer be a problem but they do not hurt.
- CPUFREQ is the frequency of your CPU (in Mhz) – this is very useful for timing information. (Taken from /proc/cpuinfo if available, sysctl -a on MacOSX.)
- GIT_REVISION and GIT_URL provide binary_c with information about the version of the code you are using. This can prove essential when debugging. See section 13.18 for more details.
10.4 binary_c_code_options.h¶
This contains non-physics options. You probably do not want to change this file unless you have compilation problems or you want to optimize the code (even more!). Some perhaps-useful options are the following:
- SEGFAULTS This should be set if want segfaults on a code failure. This is useful if you are debugging with gdb.
- ACML should be set if you wish to use the AMD math (sic) library. Note: this has not been tested for a long time.
- DUMA should be set if you wish to use the DUMA memory checking library. Note: this has not been tested for a long time.
- BATCHMODE Enables the interactive batch mode. This is required by some legacy codes.
- TIMEOUT_SECONDS Every time the code is run, a timer is set. If this is not reset within TIMEOUT_SECONDS seconds, binary_c is deliberately crashed. Clearly, if your star has not evolved in 60 seconds then something is wrong. By default this is zero, so is ignored.
- TIMEOUT_SECONDS_WITH_VALGRIND is like TIMEOUT_SECONDS but used when running Valgrind which requires often a lot more time.
- ALLOC_CHECKS This should be defined, it enables checks on memory allocation (which slows the code down a little bit). Note that if DEBUG is this will be set automatically.
- STARDATA_STATUS used to allow output from the stardata_status function.
- Restrict, Fastcall, Constant_function, MAYBE_UNUSED and Pure_function are used to tell the compiler if a function can use restricted memory access, should use fastcall (something to do with registers?), is a constant function, may be an unused variable or function, or is a pure function. See the gcc manual for details, or just leave them.
- MILLISECOND_RANDOMNESS Improves the resolution of the random number seed. You probably want this.
- NANCHECKS enables checks in many parts of the code for NaN (Not A Number). While this is slow it is very useful for catching bugs.
- RANDOM_SYSTEMS is used in conjunction with --repeat to run randomly chosen systems to check for bugs. I suggest you use the random_systems.pl script to generate random binaries.
10.5 binary_c_parameters.h¶
10.6 nucsyn/nucsyn_parameters.h¶
While many important options are set on the command line the options governing which nucleosynthesis algorithms to use and what to output are set in the file nucsyn/nucsyn_parameters.h. More detailed descriptions of the variables used in the code are given in section 9.
- Enable NUCSYN_FIRST_DREDGE_UP to make first dredge-up happen on the GB.
- You want this, and probably you want to enable NUCSYN_FIRST_DREDGE_UP_AMANDAS_TABLE and NUCSYN_FIRST_DREDGE_UP_ACCRETION_CORRECTION. These enable tabular lookups of the abundance changes (better than fitting formulae) and a simple prescription to deal with abundance changes due to accretion.
- NUCSYN_FIRST_DREDGE_UP_ACCRETION_CORRECTION_FROM_TAMS is similar but bases changes on the terminal-age main sequence abundances – this is better in the case of accretion of e.g. carbon (i.e. for CEMPs).
- NUCSYN_FIRST_DREDGE_UP_PHASE_IN enables a phased change of the abundance to better match detailed models (the default model assumes that 1st DUP happens instantaneously).
- NUCSYN_FIRST_DREDGE_UP_RICHARDS_TABLE should be enabled in addition to NUCSYN_FIRST_DREDGE_UP_AMANDAS_TABLE to use Richard Stancliffe’s models in place of Amanda’s when in the appropriate mass/metallicity range (down to while Amanda’s are valid only down to ).
- Enable NUCSYN_SECOND_DREDGE_UP to make second dredge-up happen at the beginning of the TPAGB. You want this.
- Enable NUCSYN_THIRD_DREDGE_UP to make third dredge-up happen during the TPAGB.
- You probably also want NUCSYN_THIRD_DREDGE_UP_AMANDA to get the intershell abundances from a table based on Amanda’s models.
- You can choose whether to get these numbers from either the old data USE_TABULAR_INTERSHELL_ABUNDANCES_KARAKAS_2002 (no s-process; use only for testing!) or the new table USE_TABULAR_INTERSHELL_ABUNDANCES_KARAKAS_2012 (with s-process, deprecates the Busso/Gallino tables which have been removed).
- MINIMUM_ENVELOPE_MASS_FOR_THIRD_DREDGEUP is the minimum mass for third dredge up, set on the command line with --minimum_envelope_mass_for_third_dredgeup or MINIMUM_ENVELOPE_MASS_FOR_THIRD_DREDGEUP_DEFAULT by default ( based on Straniero’s models).
- You have the option of defining NUCSYN_THIRD_DREDGE_UP_RICHARD instead, which uses Richard’s intershell material (but is less complete than Amanda’s tables).
- NUCSYN_THIRD_DREDGE_UP_TABULAR_NCAL should be used for tabular fits to the NCAL parameter instead of the old (dodgy?) formula fit.
- NUCSYN_THIRD_DREDGE_UP_HYDROGEN_SHELL activates the algorithm which takes into account dredge up of the hydrogen-burning shell at low metallicity. At high metallicity it is negligible. You should activate this.
- NUCSYN_THIRD_DREDGE_UP_MULTIPLIERS allows command-line modification of the amount of material dredge up. It does not hurt to define this if you do not use it.
- USE_TABULAR_INTERSHELL_ABUNDANCES forces the use of tables instead of fits to the intershell abundances: this is probably what you want (there are checks for going off the end of the tables).
- Enable PADOVA_MC1TP to use the Padova group’s rather than the (2002) fits (only for , above the difference is small anyway).
- Enable NUCSYN_TPAGB if you want to use nucleosynthesis on the TPAGB (e.g. third dredge-up and HBB).
- You can control the luminosity behaviour on the TPAGB with NUCSYN_TPAGB_LUMTYPE. If zero then an average luminosity is used, if 1 then post-flash dips are included for the first NUCSYN_PULSE_LUM_DROP_N_PULSES dips (DTFAC must be set to something small e.g. 0.1 to resolve the dips). The drop is by a factor THERMAL_PULSE_LUM_DROP_FACTOR and the luminosity rises again on a timescale 1/THERMAL_PULSE_LUM_DROP_TIMESCALE of the interpulse period. The spiky_luminosity variable in each star structure follows the luminosity changes. It is impossible to put the changes in the luminosity itself because the timestep becomes very small when the luminosity (and so radius) changes suddenly._
- NUCSYN_SMOOTH_AGB_RADIUS_TRANSITION smooths the transition between Hurley and Karakas and : it’s a bit of a fudge (uses NUCSYN_SMOOTH_AGB_RADIUS_TRANSITION_SMOOTHING_TIME).
- NUCSYN_TPAGB_MIN_LUMINOSITY is a minimum luminosity for TPAGB stars, a bit of a fudge, usually .
- MAX_TPAGB_TIME the maximum time (in years) for which the TPAGB phase is allowed to run, just in case something goes wrong, default is .
- NUCSYN_ROBS_REFITTED_TPAGB_INTERPULSES enables updated fits for the interpulse period.
- MINIMUM_INTERPULSE_PERIOD is the minimum interpulse period, default
- Enable NUCSYN_TPAGB_HBB if you want to HBB on the TPAGB. Choose either the analytic burning method, NUCSYN_ANAL_BURN, or the numerical solver NUCSYN_NUMERICAL_BURN. The latter has proved to be reliable, and more flexible, so I would go with that.
- If you choose NUCSYN_ANAL_BURN you can specify which nuclear reactions to include: NUCSYN_TPAGB_HBB_CN_CYCLE and NUCSYN_TPAGB_HBB_ON_CYCLE are the CN and ON parts of the CNO cycling in HBB, NUCSYN_TPAGB_HBB_NeNa_CYCLE activates the approximate NeNa cycling, NUCSYN_TPAGB_HBB_MgAl_CYCLE activates the approximate MgAl cycling. Enable NUCSYN_CNO_ASSUME_STABLE to assume solutions of the CNO quadratic are always real (i.e. a stable solution, neglect the oscillating parts), NUCSYN_NENA_LEAK will allow leakage from NeNa to MgAl (do this), NUCSYN_Na22_EQUILIBRIUM will force Na22 into equilibrium (otherwise it is not calculated because it is unstable and you probably do not care), NUCSYN_Al26m follows the metastable state of (again, do you care? it makes little difference except at low ) and NUCSYN_MGAL_LEAKBACK allows the reaction, which should be negligible.
- If you choose NUCSYN_NUMERICAL_BURN then most of the above options are automatically taken into account by the burning schemes. However, you can choose your schemes with NUCSYN_NETWORK_PP (
-chain), NUCSYN_NETWORK_COLDCNO (cold CNO cycle, which is sufficient for temperatures less than
), NUCSYN_NETWORK_HOTCNO (hot CNO cycle, explicitly includes
decays and is probably not necessary for most purposes) and NUCSYN_NETWORK_NeNaMgAl (NeNa and MgAl cycles/chains).
NUCSYN_NORMALIZE_NUCLEONS preserves the number of nucleons in the burning routine, which should prevent numerical errors.
- Further, NUCSYN_HBB_RENORMALIZE_MASS_FRACTIONS will renormalize the total mass fraction to one in order to remove some errors.
- NUCSYN_S_PROCESS activates the elemental -process, you might well want this.
- Enable NUCSYN_STPAGB for STPAGB stars. There are many associated options which you should not play with.
- The NUCSYN_HS_LS_LOG is an option for s-process logging and outputs the value of , and (see e.g. , 1998).
- NUCSYN_RADIOACTIVE_DECAY allows decay of isotopes.
- NUCSYN_FORCE_DUP_IN_COMENV forces dredge up when a common envelope forms. This seems likely, as a companion star spiralling in will mix up the envelope.
- NUCSYN_WR switches on the massive star (and WR/Helium star) code. NUCSYN_WR_METALLICITY_CORRECTIONS switches on the extension to this code. NUCSYN_WR_LOG outputs some information during the O/B or WR phase. NUCSYN_WR_TABLES uses tabular values instead of fits (please use this) and NUCSYN_WR_RS_TABLE enables Richard Stancliffe’s tables (this code is in testing).
- NUCSYN_NOVAE and NUCSYN_SUPERNOVAE switch on the novae and supernovae respectively. You should enable NUCSYN_NOVAE_FROM_TABLES to use tables instead of fits.
- For core-collapse supernovae choose either NUCSYN_CCSNE_WOOSLEY_WEAVER_1995 or NUCSYN_CCSNE_CHIEFFI_LIMONGI_2004.
- In the case of NUCSYN_CCSNE_WOOSLEY_WEAVER_1995 you can choose to use their NUCSYN_SUPERNOVAE_CC_WW95_A or B or C models.
- In the case of NUCSYN_CCSNE_CHIEFFI_LIMONGI_2004 you can either use their yields directly (best to do this as then the yields really are a function of mass cut) or use the Portinari-corrected versions which are less accurate (NUCSYN_CCSNE_CHIEFFI_LIMONGI_2004_PORTINARI). Define NUCSYN_CCSNE_CHIEFFI_LIMONGI_2004_EXTRAPOLATE to extrapolate beyond the end of their table at the high metallicity ( ) end.
- NUCSYN_SN_REDUCE_SODIUM reduces the sodium yield: avoid this.
- NUCSYN_LIMIT_SN_TYPES allows you to exclude SN yields from various types on the command line
- NUCSYN_R_PROCESS allows -process yields: choose from NUCSYN_R_PROCESS_ARLANDINI1999 or NUCSYN_R_PROCESS_SIMMERER2004. You also need to choose NUCSYN_R_PROCESS_FROM_SNE_MASS which is the mass of -process material ejected in the SN, typically I choose but this is quite arbitrary.
- NUCLEAR_REACTION_RATE_MULTIPLIERS allows you to change nuclear reaction rates on the command line (see , 2007 for the reasoning).
- NUCSYN_SIGMAV_PRE_INTERPOLATE allows interpolation of the nuclear cross section from a pre-calculated table, rather than a recalculation of the values from analytic formulae as a function of temperature. This is about quicker. You can change the resolution in with NUCSYN_SIGMAV_INTERPOLATION_RESOLUTION and you should enable NUCSYN_SIGMAV_INTERPOLATE_LOGT9 and NUCSYN_SIGMAV_INTERPOLATE_LOGSIGMAV so the interpolations are done in log space. SIGMAV_TINY ( ) is a minimum value for the cross section. Enable NUCSYN_HOT_SIGMAV if you want to use high-temperature ( ) reaction rates (otherwise don’t calculate them, because it’s slower). Enable NUCSYN_THERMALIZED_CORRECTIONS for high temperature reactions (not normally required).
- Enable NUCSYN_ALLOW_NO_PRODUCTION to prevent the surface abundances from changing if --no_production is used on the command line.
- NUCSYN_LOW_MASS_STRIPPING is used to change surface abundances as a function of mass stripped for star 1 and only for low mass. It is based on a lookup table of TWIN-code results. It is a temporary fudge for a particular problem and you probably do not want it.
- There are various logging options. NUCSYN_LOGGING should be defined if you want any output at all.
- NUCSYN_YIELDS should be used if you want to calculate the yield from each star. Note that yields are calculated for each single star and the whole binary system separately.
- NUCSYN_LOG_BINARY_MPYIELDS outputs the yield for the binary system (if NUCSYN_YIELDS and NUCSYN_LOG_YIELDS are defined).
- NUCSYN_LOG_YIELDS outputs the yields at every timestep (warning! this is a lot of output since it applies to all the isotopes, perhaps run through gawk to reduce the output) if NUCSYN_YIELDS is defined. If NUCSYN_YIELDS is defined and NUCSYN_LOG_YIELDS is not defined then the yields will be output at the end of the evolution time – this is the usual case.
- NUCSYN_LOG_BINARY_X_YIELDS outputs the mass ejected from the binary.
- NUCSYN_LOG_SINGLE_X_YIELDS outputs the mass ejected from each star.
- NUCSYN_LOG_MPYIELDS outputs the yield for each star.
- NUCSYN_LOG_DX_YIELDS outputs the mass ejected from each star for each timestep.
- NUCSYN_SHORT_LOG outputs some stuff about the stars (usually in the TPAGB phase)
- NUCSYN_LOG outputs more stuff.
- NUCSYN_LONG_LOG outputs even more stuff.
- NUCSYN_J_LOG outputs some stuff for J-type stars.
- NUCSYN_S_PROCESS_LOG outputs some stuff to do with the s-process.
- NUCSYN_STRUCTURE_LOG outputs stuff to do with the stellar structure.
- NUCSYN_XTOT_CHECKS is supposed to check that (i.e. the mass fractions add to ) all the time. This has not been used in a long time… so do not be surprised if it fails!
- NUCSYN_CEMP_LOGGING and associated options are for the CEMP papers. Do not use these, they are experimental.
- NUCSYN_PLANETARY_NEBULAE provides some information about PNe formation.
- NUCSYN_TPAGB_RUNTIME provides information about the time the code spends in the nucsyn_tpagb function.
- NUCSYN_ID_SOURCES is used to identify where the yields come from and is extremely useful.
- CONSMASS is activated to check whether mass is conserved when a call is made to the nucsyn_binary_yield function. If you find you are losing mass somewhere then this is probably a bug (or a numerical error, in which case you should try to fix it!) so activate CONSMASS and the code will dump out when there is missing mass. See the nucsyn_binary_yield function for details. CONSMASSDM is an extension to this but I cannot remember what it does.
- MIXDEBUG outputs some debugging information in the mixing routines, but there’s a lot of data... MIXLOG is supposed to be a shorter version but I haven’t used this for ages so it might not work. MIXDEBUG is usually set in the routine you are considering rather than here because if it is activated in nucsyn.h then it will be passed to all routines.
- AMU_GRAMS and ANU_MEV are constants and should not be changed! They give the atomic mass unit in grams and MeV.
- NUC_MASSES_DEBUG enables debugging in the nuclear mass setting code.
- NUCSYN_TPAGB_EDDINGTON_CHECKS does something to tell you whether your AGB star exceeds the Eddington limit.
- NUCSYN_GCE enables other options which are used in my GCE code. Do not touch this unless you know what you are doing.
- NUCSYN_ROTATION_EFFECTS simulates extra production at low- . Do not touch.
- NUCSYN_HUGE_PULSE_CRISTALLO Enables a huge third dredge up based on Sergio Cristallo’s models. Experimental.
- NUCSYN_CONVECTIVE_MIXIN Instead of mixing material into the whole envelope (as the original thermohaline mixing routine does) this uses the estimate of the convective envelope given in mrenv and mixes into that instead. Requires that you turn off thermohaline mixing (see MAYBE_NO_THERMOHALINE_MIXING and the --no_thermohaline_mixing 1 command-line option).
- NUCSYN_STAR_BY_STAR_MATCHING Enables some code to match stars to given observations.
- NUCSYN_SAFE_XSURF is defined if there is no possibility of a feedback loop which used to occur in the nucsyn_WR functions. Newer versions avoid this by using NUCSYN_WR_TABLES and so it should defined if NUCSYN_WR_TABLES is defined.
- NUCSYN_MU_FUZZ blurs the condition for accretion layers to sink to prevent unecessary calculations.
- MATTSSON_MASS_LOSS experimental mass-loss rates from Lars Mattsson (based on carbon abundances).
- LITHIUM_TABLES experiments to introduce lithium as a function of mass and pulse number in HBBing stars.
Now you have edited this file to your specifications you need to rebuild the code.
There are further options in the file binary_c_parameters.h (details below) although it’s unlikely you’ll want to change any of them.
10.7 Colours in binary_c output¶
The output from binary_c
, especially the standard log file and debugging output, by default makes use of ANSI terminal colours. From version 2.2 you can change each of these colours to whatever you wish which is especially handy if you are colourblind. You can list the colours available with,which shows something like,The colours are referred to internally by macros BLACK, RED, etc. and the colour strings are stored in stardata->store->colours[n] where n is replaced by one of the macros of the number they represent (BLACK is 0, RED is 1 etc.).
./binary_c version | grep ANSIANSI colour 0 BLACK : Default is [0;30m, we are using [0;30m.
ANSI colour 1 RED : Default is [0;31m, we are using [0;31m.
ANSI colour 2 GREEN : Default is [0;32m, we are using [0;32m.
...You can change these on the command line, e.g.,where colour2 means GREEN (see above) and 12 is the colour’s new ANSI 8-bit code (in the range 0 to 255). The ANSI colours are defined at https://en.wikipedia.org/wiki/ANSI_escape_code#8-bit.
./binary_c colour2 12If a colourblind user would like to set up a palette that works for them, I would be very happy to program this in for you.
Note: if you simply wish to output the log file without colour, try
./binary_c ... colour_log Falsetop11 binary_c software development ¶
This section describes the binary_c
software development cycle.
11.1 The git revolution¶
In its earliest days, I was the only person using binary_c
. It didn’t really work properly, so this was not surprising. As time went on, I aged and other, younger people started using binary_c
. While this is great, it puts some burden on me as the maintainer. However, there is a better way! The decision was made to put binary_c
into subversion (SVN) and all
14
was solved. We have since moved to gitlab.com’s servers which provide excellent open-source support.Well, some…
You could use a graphical interface, such as Gitkraken, to work with git – this may save you a lot of time and effort!
11.2 The master (trunk)–branch model¶
Code on git is like a tree. The main version of binary_c
resides in the master
version (like SVN’s trunk). When you first requested access to binary_c
, Rob will have made you a copy of the latest master
version. This copy is called your branch. You could, in theory, have more than one branch, like a real (healthy) tree, but most people have just one branch.
To get binary_c
using SSH run
git clone git@gitlab.com:binary_c/binary_c.gitgit clone https://gitlab.com/binary_c/binary_c.gitIn your branch you can do whatever you like! Change the code, delete things, make new things, whatever. It’s your branch. But, beware. You will want bug fixes to merge easily, so don’t change your branch too radically, and make sure you update with changes from master regularly (see Section 11.2.1 below).
Apologies to those who disagree with the use of master
rather than, say, main. The use of this word is a historical artefact decided by git back in the distant past. Were we able to change this without possibly breaking existing software, especially older versions of scripts, code, Dockers, etc., we would. You can always set up your own git branch alias to change the name locally to something more acceptable to you.
11.2.1 Updating with the latest fixes¶
The master
is periodically updated with fixes. Only Rob can do this because someone has to be the administrator. However, he posts to the binary_c
Slack to describe what he has done. Now, let’s say you want to merge these fixes with your branch. You have to, from your branch directory, do
git mergeBeware: there may well be conflicts with your code – git will inform you. git tries very hard to merge code automatically, but sometimes this just is not possible. You have to fix these files and then tell git they are fixed.
Rob assumes you merge the master regularly and often. If you leave a long time between merging you will have problems, often because something in the code on which you rely has been changed (hopefully for the better). Do not let this happen! Merge regularly and often.
11.2.2 Committing your changes¶
When you make changes in your branch, you should commit your code. Do this with
git commitgit commit -aYou should commit regularly and often. You then have a backup of your code for free!
11.2.3 Submitting changes to the master ¶
Only Rob can/should make changes to the master
. If you are ready to have your changes incorporated into the main version of binary_c
which, need I remind you, you are obliged to do by the terms of the licence agreement, you should do the following:
- Run to make sure you have the latest version of your code.
git pull - Test your code to make sure it works as you expect.
- Run to commit your code. Note that this does not send any information to the server, it is all done offline until you push you code (see below).
git commit -a - Run to merge all the latest changes into your code.
git merge - Fix any conflicts, test the code, make sure it works as you expect even with the latest changes to master.
- Run to send code to the server.
git push - Email Rob, tell him your branch is ready to commit, and tell him the git revision number of your last commit. You can also submit merge requests via the gitlab interface.
The rest is Rob’s job. If you want another branch to work on while you wait, just construct it as usual.
11.2.4 Getting your old code back¶
If you make a mistake, you can always get your old code back. Have a look at the and
git checkoutgit revert11.3 Unit testing¶
It is difficult to say what is “right” when testing binary_c
output because anyone could change anything in the code: is this correct? I have no idea. However, we have a number of unit tests you can run.
11.3.1 Unit test arguments¶
The command-line arguments that define each test are in $BINARY_C/unit_tests/argument_lists. Each file contains simply a list of arguments. You should make sure the filename is meaningful, as this is used to identify the test.
11.3.2 Unit test reference data¶
When running unit tests, we compare to reference data. The files containing the reference data are in $BINARY_C/unit_tests/reference_data.
11.3.3 Running unit tests¶
To run the tests
cd $BINARY_C ./src/python/do_unit_tests.py
11.3.4 How unit testing works¶
The logfile of each system run with binary_c
is converted into a Python dict of statistics using binary_c_log_to_dict.py. These dicts are compared to the reference output using binary_c_dictdiff.py which is a wrapper for Python’s Deepdiff module. This allows a floating-point comparison to within a threshold rather than a test for equality. You can change this threshold in the diff_args variable in do_unit_tests.py.
top12 Troubleshooting / Frequently-asked questions¶
- When installing and running binary_c-python, I receive the error
libjemalloc.so.2: cannot allocate memory in static TLS blockexport GLIBC_TUNABLES=glibc.rtld.optional_static_tls=10000top13 Cookbook¶
This section provides ideas for common obvious problems.
13.1 How to log output¶
Put your logging statement into log_every_timestep.c using the Printf macro, e.g.,
Printf();13.2 How to find which source files contain a string¶
Run
./rgrep <string> {opts}./rgrep <string> -i13.3 How to build with debugging output¶
Please see 9.5.3.
13.4 How to check for NaNs (not a numbers)¶
If NANCHECKS is enabled in binary_c_code_options.h you can use the NANCHECK(A) macro, which checks whether A is not a number, exiting with an error if this is the case. This is rather compiler dependent but should work fine with gcc.
13.5 How to exit binary_c ¶
Do not use C’s exit function. Instead use the Exit_binary_c(…) macro, with an error code from binary_c_error_codes.h, e.g.
Exit_binary_c(PIPE_FAILURE, “My pipe failed! ARGH!”);13.6 How to debug segfaults¶
Install gdb. Build binary_c
with debugging:
cd builddir
meson setup --reconfigure --buildtype=debug
ninja binary_c_install
cd ..Then run your test star with
tbse debug which will run gdb for you with the appropriate arguments to run the star. To find out where the bug is, use “bt” (backtrace) in gdb.
You may find that valgrind provides more information, especially when your segfault is caused by a memory leak.
13.7 How to debug memory leaks¶
Build with debugging:
Then run
Find out how to use valgrind at http://valgrind.org/
You can also run
cd builddir
meson setup --reconfigure --buildtype=debug -Dvalgrind=true
ninja binary_c_install
cd ..tbse valgrindYou can also run
tbse callgrindtbse cachegrindtbse ptrchecktbse sgcheck13.8 How to run through callgrind to profile binary_c?¶
As of version 2.3, we have optimized how things look in kcachegrind through a custom Python formatting script.
Build and run the following, where you may want to set the optimization level to 0 if you want to see every line of code contribute to CPU cycles. If you leave it at 2 (or higher), as is the default, then often you’ll see CPU time conglomerated because the compiler has changed your code internally. You probably want this, because you want to test binary_c
as it would be used “in the wild”.
meson setup build-callgrind-expanded --buildtype=custom -Doptimization=2 -Ddebug=true -Dvalgrind=true -Dusepch=true -Dcallgrind_expand_macros=true -Db_lto=false
ninja -C build-callgrind-expanded
tbse callgrind
kcachegrind callgrind.tbse.out13.9 How to show the arguments that tbse would use, but do not evolve a star¶
Run
tbse echo13.10 How to run a star which has the arguments in a file¶
This is handy when you have a fail case (e.g. from a population synthesis run). Just run
tbse <filename>13.11 How to use profile-guided optimization (PGO)¶
Meson supports profile-guided optimization (PGO), and this has been written into the meson/pgo.sh script which you can use to test it. You should just run this, with an optional argument that is the number of test systems (this defaults to 1000), e.g. from the binary_c
root directory:
./meson/pgo.sh 1000For details about profile-guided optimization, please see https://en.wikipedia.org/wiki/Profile-guided_optimization or your compiler’s documentation.
13.12 How to get help¶
13.12.1 How to know what a parameter does¶
Run
binary_c help <parameter_name>or
binary_c help_allYou can even just give binary_c
part of a parameter name and it will try to find the best match.
13.12.2 The mailing lists¶
There is a development mailing list for binary_c
, for details see section 1.4.
13.13 How to add a parameter/command-line argument to binary_c ¶
Parameters, also called command-line arguments, for binary_c
are stored in src/setup/cmd_line_args_list.def. Each is defined in an X-macro which looks something like the following where square brackets with pipes, e.g.
[a,b,c], indicates a choice between, in this case, a, b or c.X(
[0,1], // parse number
ARG_SECTION_[MISC|STARS|BINARY],
"argument_string",
"A description of the argument for humans",
ARG_[INTEGER|LONG_INTEGER|DOUBLE|BOOLEAN|STRING|SUBROUTINE|DOUBLE_SCANF|BOOLEAN_SCANF|INTEGER_SCANF],
[WTTS_USE_DEFAULT|"Ignore"],
(void * max_pointer|NO_MAX_POINTER),
[Var(stardata->preferences->binary_c_variable_name)|Sub(binary_c_subroutine_name)],
1.0,
CMD_LINE_ARG_T_OPTIONAL_ARGS,
[0,1,2],
ARG_RANDOM_[NONE|INT|BOOLEAN|DOUBLE|LOGDOUBLE|INT_ARRAY|DOUBLE_ARRAY|INT_ARRAY_OR_INT_SCALAR|INT_ARRAY_OR_DOUBLE_SCALAR|DOUBLE_ARRAY_OR_DOUBLE_SCALAR],
{[._int|._double]=<lower limit>},
{{._int|._double]=<upper limit>},
2,
{{[._int|.double]=<array_value1>},{[._int|._double]=<array_value2>},...}
)The best way to add a variable is to find one that is similar in src/setup/cmd_line_args_list.def and copy/paste it into the list,editing as required. A good, and simple, example is the orbital separation which is a double-precision scalar set into stardata->preferences->zero_age.separation[0] as follows:
X(
1,
ARG_SECTION_BINARY,
"separation",
"Set the orbital separation (actually the semi-major axis) of the binary (internal index 0, stellar indices 0 and 1) in solar radii. Note that if the orbital period is given, it is used to calculate the separation and the value you set with this argument is ignored. So if you want to set the separation instead, either do not set the orbital period or set the orbital period to zero (0.0).",
ARG_DOUBLE,
WTTS_USE_DEFAULT,
NO_MAX_POINTER,
Var(stardata->preferences->zero_age.separation[0]),
1.0,
CMD_LINE_ARG_T_OPTIONAL_ARGS,
CMD_LINE_ARG_T_NO_RANDOM_VARIATION
)13.13.1 Points of interest¶
- Parsing happens in series of loops over all the arguemnts. The first time is parse 0, then parse 1 etc. The parse_number is usually 0 or 1. This means that arguments with parse_number set to 0 are parsed on parse 0, then those with parse_number set to 1 on parse 1. You can also set the parse_number to ARG_PARSE_ALL to have the variable parsed every time – which may well be multiple times!.
- The sections and WTTS_USE_DEFAULT are used by external tools like WIndow to the Stars.
- The max_pointer is a maximum pointer that can be set by the argument if it is of scanf type. This prevents the user from setting an arbitrary pointer which would probably lead to a segmentation fault.
13.13.2 An argument that calls a subroutine/function¶
You can set up an argument to call a subroutine, for example the following calls set_merger_mass_loss_fraction_nondegenerate to set the merger mass-loss fraction of all non-degenerate types of star.
X(
1,
ARG_SECTION_BINARY,
"merger_mass_loss_fraction_nondegenerate",
"Equivalent to setting the merger_mass_loss_fraction_by_stellar_type for all nuclear-burning, non-degenerate stellar types (including low-mass main-sequence stars). Note: you should not combine this with attempts to set the mass loss fractions individually.",
ARG_SUBROUTINE ,an
WTTS_USE_DEFAULT,
NO_MAX_POINTER,
Sub(set_merger_mass_loss_fraction_nondegenerate),
1.0,
CMD_LINE_ARG_T_OPTIONAL_ARGS,
CMD_LINE_ARG_T_NO_RANDOM_VARIATION
)13.13.3 SCANF types: used to set array values¶
You can set macros to be SCANF types. For example, setting the argument_string to
"ensemble_filter_%d" and the type to ARG_BOOLEAN_SCANF means you can set an argument as ensemble_filter_0, ensemble_filter_1 or ensemble_filter_3 etc. with the following boolean in locations [0], [1] and [2] in the ensemble_filters array of booleans. The C sscanf function converts the final integer of the argument using the %d identifier. You have to replace CMD_LINE_ARG_T_OPTIONAL_ARGS with detailed information, and you should also set the max_pointer. These are set elsewhere (in STELLAR_POPULATIONS_ENSEMBLE_FILTER_VAR and STELLAR_POPULATIONS_ENSEMBLE_FILTER_VAR_MAX cmd_line_macros.h) using macros which depend on whether, in this case, STELLAR_POPULATIONS_ENSEMBLE is defined.
The argument definition then looks as follows:
X(
1,
ARG_SECTION_OUTPUT,
"ensemble_filter_%d",
"Turn on or off ensemble filter <n>. For a list of filters, see ensemble_macros.h.",
ARG_BOOLEAN_SCANF,
WTTS_USE_DEFAULT,
STELLAR_POPULATIONS_ENSEMBLE_FILTER_VAR_MAX,
STELLAR_POPULATIONS_ENSEMBLE_FILTER_VAR,
1.0,
NULL,0,NULL,0,ensemble_filters,STELLAR_POPULATIONS_ENSEMBLE_FILTER_NUMBER,
CMD_LINE_ARG_T_NO_RANDOM_VARIATION
)If you want to set an integer, change the type to ARG_INTEGER_SCANF and the identifier should be %d.
If you want to set a double-precision number, set the type to ARG_DOUBLE_SCANF and the identifier to (say) %g.
The max_pointer variable is very useful when you use SCANF types. Because you are setting values into an array you need to know the end of the array, otherwise imagine if the user entered an argument like
ensemble_filter_123456789! This would set the 123456789th element of the ensembles_filters array, which is way beyond the end of the array.13.13.4 set_cmd_line_macro_pairs¶
Many arguments take an integer as an option. For example, comenv_merger_spin_method takes – at the time of writing – 0, 1, 2 or 3, where each corresponds to some different physics. However, this is very difficult for a human to read and make sense of. Instead, the four following macros are defined COMENV_MERGER_SPIN_METHOD_SPECIFIC, COMENV_MERGER_SPIN_METHOD_CONSERVE_ANGMOM, COMENV_MERGER_SPIN_METHOD_CONSERVE_OMEGA and COMENV_MERGER_SPIN_METHOD_BREAKUP which correspond to 0, 1, 2 and 3 but are much easier to read.
These macros are set in the function set_cmd_line_macro_pairs which uses the macros defined by X-macros elsewhere in binary_c
:
#define X(CODE) Add_value_macro_pair("comenv_merger_spin_method",COMENV_MERGER_SPIN_METHOD_##CODE);
COMENV_MERGER_SPIN_METHODS_LIST;
#undef XYou can, if feeling adventurous, set the values in CMD_LINE_ARG_T_OPTIONAL_ARGS yourself that correspond to the above setup, but I highly recommend using the framework provided in set_cmd_line_macro_pairs instead.
13.14 How to build on a Mac¶
Please see Section 4.7 of the installation guide.
13.15 How to build binary_c as a shared library¶
The shared library is built by default when you install binary_c
with meson and ninja. You will find libbinary_c.so in the src subdirectory (for historical reasons!) and also in your build directory.
13.16 How to calculate stellar yields or population statistics¶
- You have to build binary_c with NUCSYN and NUCSYN_GCE enabled, as well as the required physics
- You have to install binary_c-python .
- Run an ensemble. See 7 for instructions.
13.17 bash autocompletion of binary_c arguments¶
You can make bash autocomplete arguments to binary_c
by putting the following in your .bashrc file (assuming you have binary_c
in the directory specified by the environment variable BINARY_C) and restart bash.
# completion of binary_c arguments
_binary_c()
{
COMPREPLY=()
cmd="${COMP_WORDS[0]}"
cur="${COMP_WORDS[COMP_CWORD]}"
prev="${COMP_WORDS[COMP_CWORD-1]}"
binaryc_opts=$($BINARY_C_ROOT/binary_c help |/bin/grep -A2 "where the arguments are a selection of :"|tail -1|tr " " "\n")
# check if we match a binary_c argument
subcmd=( $(compgen -W "$binaryc_opts" "$prev") )
if [[ $subcmd ]] ; then
# we do match an argument : try to get sub options
subopts=$($BINARY_C_ROOT/binary_c argopts $subcmd)
COMPREPLY=( $(compgen -W "$subopts" -- ${cur}) )
else
# we don't, so list the arguments
COMPREPLY=( $(compgen -W "$binaryc_opts" -- ${cur}) )
fi
return 0
}
complete -F _binary_c binary_c
complete -F _binary_c tbse
13.18 How to find the git revision and git URL¶
Put the following into your .bashrc file, restart bash and use the command git_rev to find a suitable git revision string and git_url to find the repository URL.
# git function for review number
git_rev ()
{
d=`date +%Y%m%d`
c=`git rev-list --full-history --all --abbrev-commit | wc -l | sed -e 's/^ *//'`
h=`git rev-list --full-history --all --abbrev-commit | head -1`
echo ${c}:${d}:${h}
}
# git function to find the repository url
git_url ()
{
git config --get remote.origin.url
}
13.19 Ninja autocompletion¶
Copy the file meson/bash_ninja_autocomplete.sh (in the binary_c
root directory) to wherever you keep your bash autocompletion scripts. Make it executable with and add the following to your .bashrc file:
chmod +x bash_ninja_autocomplete.sh# autocomplete for ninja source <path to file>/bash_ninja_autocomplete.sh
The autocompletion script is based on an original from https://github.com/ninja-build/ninja/blob/master/misc/bash-completion, distributed under an Apache 2.0 licence.
13.20 Meson autocompletion¶
You can find a script for meson autocompletion at meson/bash_meson_autocomplete.sh (which was downloaded from https://raw.githubusercontent.com/mesonbuild/meson/master/data/shell-completions/bash/meson). Do similarly to the ninja autocompletion script describe in section 13.19.
If you get errors like
_filedir: command not found put the following into your .bashrc before sourcing the above file,if [ -n "$BASH_VERSION" ]; then
[ -f /etc/bash_completion ] && . /etc/bash_completion
fi13.21 Clang static analyzer (scan-build)¶
You can use Clang’s static analyzer, the command scan-build, by doing the followingthis leaves the meson and ninja output in the files scan.meson and scan.ninja, and the results in the directories scan_build_results_ninja and scan_build_results_meson. Note that the -Dusepch=false flag is required to disable pre-compiled headers because the static analyzer does not understand the concept. Please use the -o option to redirect output to a more suitable location (or see https://clang-analyzer.llvm.org/scan-build.html#scanbuild_output).
rm -r builddir # may not be necessary mkdir scan_build_results_ninja scan_build_results_meson scan-build -o scan_build_results_meson -v meson setup builddir -Dusepch=false 2>&1 > scan.meson cd builddir scan-build -o ../scan_build_results_ninja ninja -v 2>&1 > ../scan.ninja
13.22 Memory leak or memory bloat?¶
All software is liable to memory leaks, that is when memory is allocated but not freed. When running a grid of stars using binary_c-python
this is particularly problematic: if binary_c
leaks
per star – not much in the modern world! – and you are running
stars this is
of memory, which may slow your system or even cause it to crash if you are running many threads (each of which suddenly wants the memory).
However, not all memory “leaks” are as they seem, they may just be “bloat”. The way binary_c-python
works is to run a star using binary_c
which collects its output in a buffer. This buffer is then passed from binary_c
to binary_c-python
which splits it into lines that are processed by your grid script. This works, provided the buffer is not too large
17
. You might argue it is inefficient: and you would be right! In terms of memory, it is wasteful. But in terms of speed, which is usually more important, it is not: it is quick and what’s more it is simple.The maximum buffer size is set by BUFFERED_PRINTF_MAX_BUFFER_SIZE which you can find by running
./binary_c version |grep BUFFERED_PRINTF_MAX_BUFFER_SIZE.The problem is that the way memory is allocated in operating systems is typically that it goes up, not down, so once the buffer is allocated it stays that way (even if binary_c
frees the memory, the operating system keeps it assigned to the process). The trick then is to not use the buffer much in the first place! This means you should only output when you need to. Outputting every timestep is likely to get you into such trouble: you have no idea a priori how many timesteps there may be: it could be tens, could be thousands.
How can we mitigate this problem? The most obvious way is to output only when something interesting is happening for you. Check the example code in src/logging/log_every_timestep.c. You can also set up timestep triggers as described in Sec. 9.7.1 so that output is only at certain times (in linear or logarithmic time). For example, if you output every
and have a maximum evolution time of
, you know you will have
lines of output, no more
18
.You may have more if you are using evolution splitting, but most simulations do not use this feature.
The other option is to buy more RAM. It’s cheap, but not free. Remember though, moving memory around also costs you CPU cycles. Indeed, much of binary_c
’s time is spent doing memcpys: you want to avoid this if you can, just learn to be efficient.
top14 Changelog¶
Note this is always an incomplete list!
- Version 2.2
- Stellar population ensembles using libcdict. Many code improvements (e.g. interaction with the YBC library). binary_c-python and (many) associated tools. Deprecated binary_grid .
- Version 2.1
- Time integration is now forward-Euler, RK2 or RK4, rationalised the time evolution loop, events subsystem introduced, fixed timesteps now standard, command line macros, update mass transfer rates, many bug fixes.
- Version 2.0
- Finally, RGI had some time to sit down and redesign the guts of binary_c . Version 2.0 is a cleaned up, sensible version of the old code. It has better logic, naming, time resolution, setup, etc.
- Version 1.2prexx
- Lots of updates! CEMPs project (Utrecht), experimental stuff to better model rotation, tables replace many fits (e.g. nucsyn_WR), interaction with binary_grid Perl module for population synthesis, external users (Selma, Joke, Carlo).
- Version 1.2
- Include STPAGB stars, batchmode and grid.pl references, spiky_luminosity, removal of the adaptive grid. Also mention gce.pl.
- Version 1.1
- Minor changes to include support for variation of initial abundances via command-line switches for Hilke’s GCE project.
- Version 1.0
- The original version.
top15 Acknowledgements¶
This document was prepared using the wonderful LyX.
topReferences¶
Arlandini et al. 1999, "Neutron Capture in Low-Mass Asymptotic Giant Branch Stars: Cross Sections and Abundance Signatures", 525 (1999), pp. 886-900.
Chieffi and Limongi 2004, "Explosive Yields of Massive Stars from Z=0$ to Z = Z_{\odot}$", 608 (2004), pp. 405-410.
De Donder and Vanbeveren 2002, "The chemical evolution of the solar neighbourhood: the effect of binaries", New Astronomy 7 (2002), pp. 55-84.
De Marco and Izzard 2017, "Dawes Review 6: The Impact of Companions on Stellar Evolution", 34 (2017), pp. e001.
Dray et al. 2003, "Chemical enrichment by Wolf-Rayet and asymptotic giant branch stars", 338 (2003), pp. 973-989.
Gallino et al. 1998, "Evolution and Nucleosynthesis in Low-Mass Asymptotic Giant Branch Stars. II. Neutron Capture and the s-Process", 497 (1998), pp. 388.
Hurley et al. 2002, "Evolution of binary stars and the effect of tides on binary populations", 329 (2002), pp. 897--928.
Ivanova et al. 2013, "Common envelope evolution: where we stand and how we can move forward", 21 (2013), pp. 59.
Iwamoto et al. 1999, "Nucleosynthesis in Chandrasekhar Mass Models for Type IA Supernovae and Constraints on Progenitor Systems and Burning-Front Propagation", 125 (1999), pp. 439-462.
Izzard and Jermyn 2022, "Circumbinary discs for stellar population models", (2022).
Izzard and Tout 2003, "Nucleosynthesis in Binary Populations", 20 (2003), pp. 345-350.
Izzard et al. 2004, "A New Synthetic Model for AGB Stars", 350 (2004), pp. 407-426.
Izzard et al. 2006a, "Galactic Sodium from AGB Stars", ArXiv Astrophysics e-prints (2006).
Izzard et al. 2006b, "Population nucleosynthesis in single and binary stars. I. Model", 460 (2006), pp. 565-572.
Izzard et al. 2007, "Reaction rate uncertainties and the operation of the NeNa and MgAl chains during HBB in intermediate-mass AGB stars", 466 (2007), pp. 641-648.
Izzard et al. 2009, "Population synthesis of binary carbon-enhanced metal-poor stars", 508 (2009), pp. 1359-1374.
Izzard et al. 2012, "Common envelope evolution", in IAU Symposium vol. 283, (2012), pp. 95-102.
Izzard et al. 2018, "Binary stars in the Galactic thick disc", 473 (2018), pp. 2984-2999.
José and Hernanz 1998, "Nucleosynthesis in Classical Novae: CO versus ONe White Dwarfs", 494 (1998), pp. 680.
Karakas et al. 2002, "Parameterising the third dredge-up in asymptotic giant branch stars.", 19 (2002), pp. 515-526.
Livne and Arnett 1995, "Explosions of Sub--Chandrasekhar Mass White Dwarfs in Two Dimensions", 452 (1995), pp. 62.
Simmerer et al. 2004, "The Rise of the s-Process in the Galaxy", 617 (2004), pp. 1091-1114.
Woosley and Weaver 1995, "The Evolution and Explosion of Massive Stars. II. Explosive Hydrodynamics and Nucleosynthesis", 101 (1995), pp. 181.
Woosley et al. 1986, "Models for Type I supernova. I - Detonations in white dwarfs", 301 (1986), pp. 601-623.